Why Your AI Stack is Broken — And How One Database Platform Can Fix it

This blog was co-authored by Dave Stone and Neel Chopra.
Explore why centralizing on Postgres with EDB Postgres AI is key for delivering GenAI applications faster than the competition.

Are you tired of watching your AI projects not cross the finish line? You're not alone. Many organizations struggle to translate the promise of AI into tangible results, and a key reason lies beneath the surface of the models themselves: the data they access and are trained on. The strength of generative AI (GenAI) applications, in particular, is directly linked to the quality and accessibility of their data. This understanding is driving significant investment, with Menlo Ventures reporting an 8x increase in data and infrastructure to support GenAI in 2024 compared to 2023.
With so much value placed on the data behind AI models, how you store and access that data is fundamental to your success, but the options can be overwhelming. You could go with cloud data platforms like AWS, Databricks, or Snowflake. You could opt for a specialized vector database like Pinecone or Milvus. There are open source options like Postgres with the pgvector extension. Or you could leverage NoSQL databases like MongoDB and Redis — and the list goes on. Unfortunately, most companies end up using a messy combination of these point solutions. This fragmented approach forces your teams to learn new skills, sift through mountains of information, and waste time on complex data management, resulting in longer development cycles and slower time-to-value.
Let’s dig deeper into the challenges of fragmentation — and then discover how EDB Postgres AI solves them.
How Sprawling, Single-Purpose Data Stores Create Innovation Bottlenecks
With data coming from over 400 different sources, and data volume growing more than 60% month over month, it’s no surprise that data management complexity is one of the primary bottlenecks customers face with GenAI application development. Development teams must spend valuable cycles on extensive integration work, like building custom connectors, normalizing data formats, and moving data across siloed systems, instead of focusing on core AI innovation. This operational overhead hampers competitive positioning, limits ROI, and slows time-to-market — and such a complex web of point-to-point integrations becomes increasingly difficult to maintain and scale as your AI initiatives grow.
To characterize these challenges with an example, according to a recent study by McKnight Consulting Group, organizations using a cloud-based, piecemeal approach for GenAI deployments face 3x higher development complexity and 1.6x higher maintenance complexity compared to a single database with AI tools natively available.
Now let’s look at the specific implications of these data management challenges for AI.
Two Critical Challenges with Your Data in AI Development
Everyone talks about AI, but are they really discussing the same thing? In boardrooms and tech conferences across the globe, "AI" has become the buzzword that promises to transform everything. Yet beneath this universal excitement lies a fundamental confusion that hampers real progress. When we talk about AI, we're actually discussing two distinct but interconnected aspects that require very different approaches: training and inference.
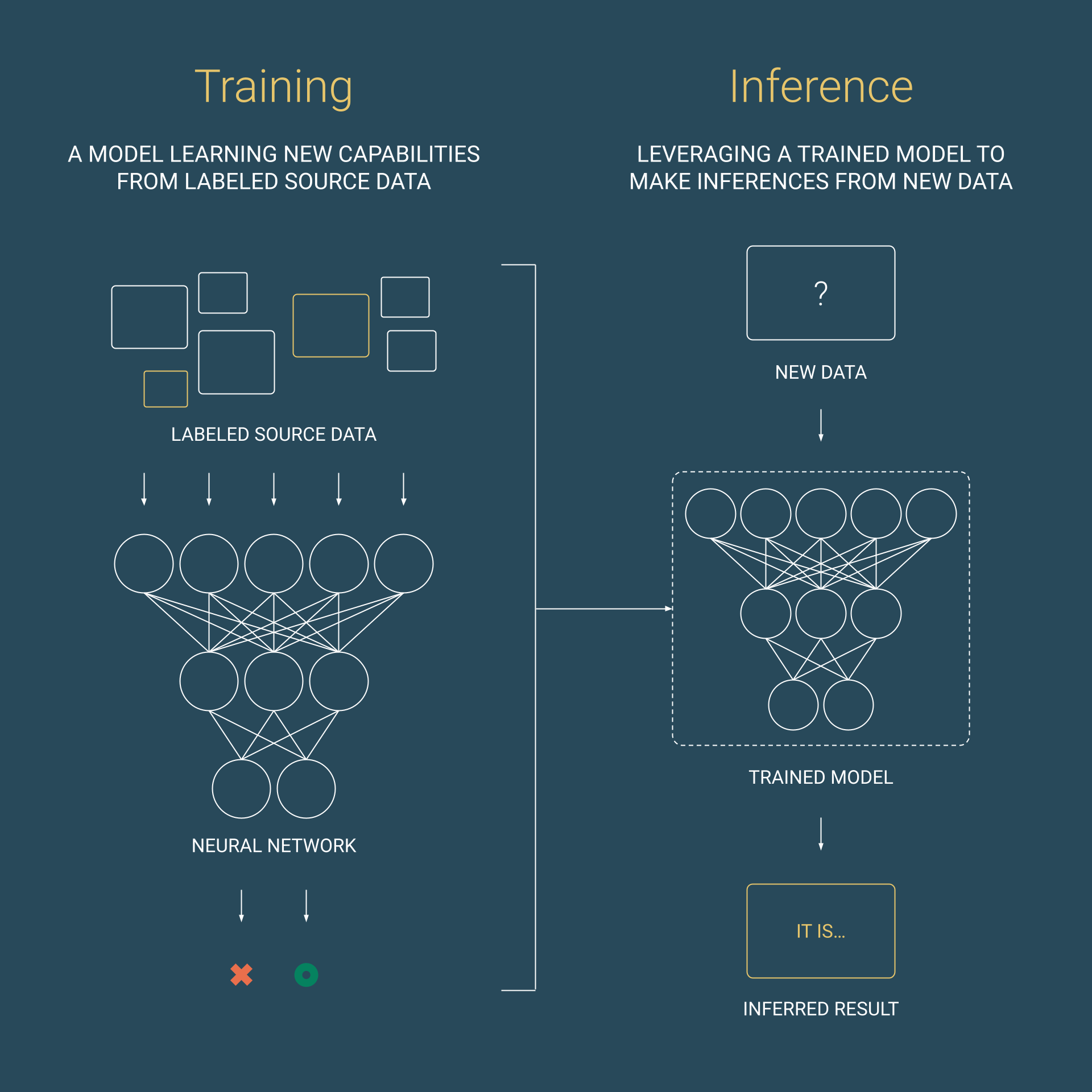
Challenge 1: Storing and Accessing Data for AI Model Training
The first AI data management challenge involves the foundational work — the careful curation, organization, and preparation of massive datasets that teach models to recognize patterns, make predictions, and understand context. This process requires robust infrastructure that can handle diverse data types and massive scale.
Challenge 2: Taking Action with GenAI Inferencing
The second data management challenge focuses on what has caught the mass market's attention with OpenAI and others. This is where the rubber meets the road — leveraging those trained models to generate new content, make recommendations, automate decisions, and create new value based on new data inputs in real-time applications.
These two data problems require fundamentally different infrastructure approaches, which can further exacerbate data and vendor fragmentation as enterprises struggle to adapt their existing data management techniques. These mounting obstacles illustrate why, according to Gartner, 30% of GenAI projects are abandoned after proof of concept.
So, how can you overcome these hurdles and achieve AI success? The key lies in a unified database strategy that’s future-proof for all storage and access needs. For the inference side of AI, read about how EDB Postgres AI Factory can simplify and accelerate GenAI application development — and read on here for a closer look at how EDB Postgres AI Database can streamline source data storage and access for training purposes.
How EDB Postgres AI Simplifies Data Management in the AI Era
EDB Postgres AI accelerates AI development by simplifying data management with a unified data store. Traditionally, preparing data for AI model training has been a complex, resource-intensive process, forcing developers to spend time searching, sorting, and building elaborate data transfer mechanisms. EDB Postgres AI solves this by centralizing both structured data (like relational database tables), unstructured data (like images), and semi-structured data (like JSON) — enabling a single, streamlined connection between your AI model and its training data. This significantly reduces preparatory tasks and optimizes the entire training process.
With that in mind, let's examine some more specific use cases.
Leverage a Unified Query Engine
EDB Postgres AI empowers developers to standardize on a single data store for transactional, analytical, and AI workloads. But how do you actually read and access this diverse data? You need a unified query engine.
Without such an engine, teams typically juggle various APIs and programming languages to pull information from multiple, disparate sources. The EDB Postgres AI engine acts as a centralized interface, simplifying data access for developers.
This unified query engine is comprised of three essential components, each designed for specific data access needs:
- Postgres Query Engine: Provides the foundational transactional and core data management capabilities.
- Analytics Engine: Enables high performance on large-scale analytical queries across diverse datasets, including data lakes.
- Agentic Search: Leverages AI for natural language interaction, translating complex questions into actionable queries across all data sources and synthesizing intelligent, context-rich answers for AI applications.
By providing a single interface for developers to access their data, EDB Postgres AI unifies all workloads, preventing unnecessary data silos and fragmentation. Additional benefits include complete data sovereignty and intelligent AI Knowledge Bases that automatically handle vector similarity calculations for you. Ultimately, EDB Postgres AI delivers improved operational efficiency, flexibility, and scale for building innovative AI applications. This unified approach allows you to feed models with training data from a variety of sources, seamlessly.
Modernize from Oracle to Postgres to Accelerate GenAI Development
EDB Postgres AI offers a compelling solution for migrating from Oracle to Postgres, serving as a unified data store for both transactional workloads and GenAI application development. But why should you make the switch?
Oracle users frequently encounter challenges with high costs and limited data model support. These constraints become particularly problematic when developing AI applications that require diverse data types and flexible storage options. When you have all your diverse data types available in a single platform, you can train more comprehensive AI models, perform cross-dataset analytics, and build applications that leverage the full spectrum of your organization's data without complex integrations.
The USDA Forest Service demonstrates these benefits in practice. When Oracle discontinued support for geospatial data — a vital requirement for their forest management operations — they needed a database that could handle diverse data types without compromise. By migrating to EDB Postgres AI, they not only solved their geospatial data challenge through the PostGIS extension, but also achieved a 70% boost to performance while reducing costs by 30%.
Transform Your AI Development Today
Your AI stack doesn't have to remain broken. The fragmented approach to data management that plagues most organizations creates unnecessary complexity, increases costs, and slows down innovation. By consolidating your data infrastructure around EDB Postgres AI — a single, powerful database platform — you eliminate the bottlenecks that prevent your AI projects from reaching production. Your developers can focus on modern data and AI initiatives instead of wrestling with data integration challenges.
The evidence speaks for itself: organizations using a unified data platform for GenAI development see 67% lower development complexity and 38% lower maintenance complexity compared to fragmented DIY approaches.
Ready to fix your AI stack? Explore EDB Postgres AI to see how a unified data platform can simplify data management and accelerate GenAI development. Take a look at our Migration Handbook to learn how you can transition from fragmented systems to a streamlined, AI-ready infrastructure. You can also schedule a consultation with our experts to discuss your specific AI data challenges and discover how EDB Postgres AI can transform your development process.