EDB Postgres Distributed: Understanding Conflicts and Their Resolution

Users of EDB Postgres Distributed (PGD) typically use a write-leader for a cluster, which is a node elected by Raft to do writes to the database. Even when a write-leader is configured per region or per subgroup, each write-leader writes to different schemas or different tables. When a crash or network partition causes a write-leader to change from one node to another, there can be conflicts. Thus conflicts are not supposed to be a common occurrence. If conflicts occur frequently, it is indicative of a problem in the correct use of PGD.
Conflicts have a default resolution and that can also be changed. A concise and complete summary of conflicts exists in the PGD documentation. Conflict handling has two aspects: detection and resolution.
The goal of this blog is to understand commonly occurring conflicts with examples of how they are detected and how the default conflict resolution works. Custom resolution of conflicts is discussed in the documentation.
Conflicts
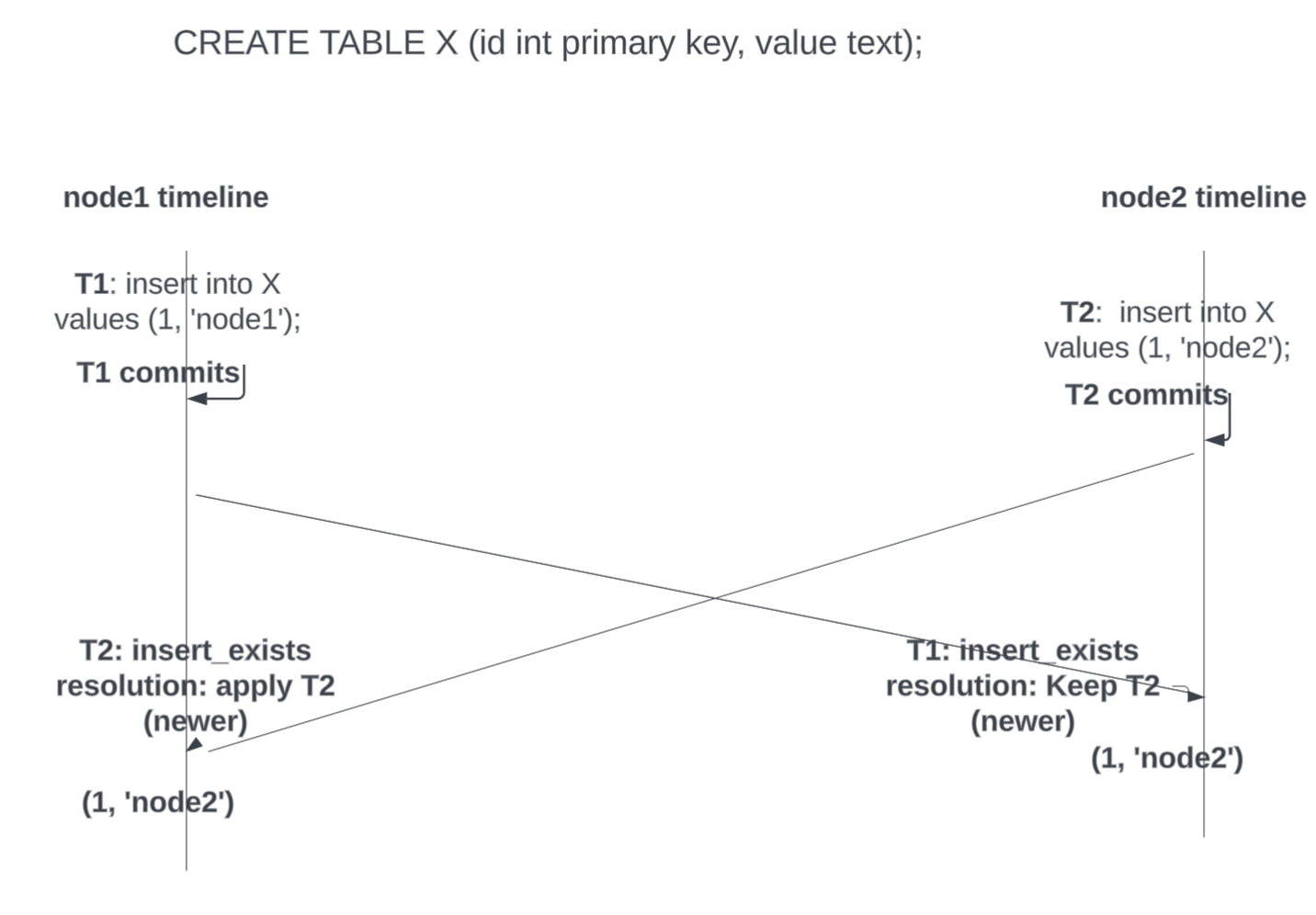
insert_exists
This is a straightforward conflict that occurs when two nodes can try to insert the same row. It is possible to know it is the same row only if the row has a unique constraint. The insert with the latest commit timestamp will be retained on each node. If there is no unique constraint, there is no conflict and the row will be simply inserted. Timestamp is of the origin which commits it. In general, we could end up comparing timestamps of two different nodes, and this may result in a newer tuple getting overwritten by an older one, if there is time skew. But this will never result in data divergence (two nodes making different decisions) because all nodes compare the same two entities and will end up with the same decision.
update_origin_change
This is the most common conflict seen. It is not indicative of a problem, but it is important to understand what this can lead to.
The definition says: An incoming update is modifying a row that was last changed by a different node. A change of origin means the previous version of this row was added by a different origin and could be an indicator of conflict.
This is seen on tables that have one or more unique constraints, which may also include a primary key. A write leader change can cause this conflict. The following example shows how this is seen.
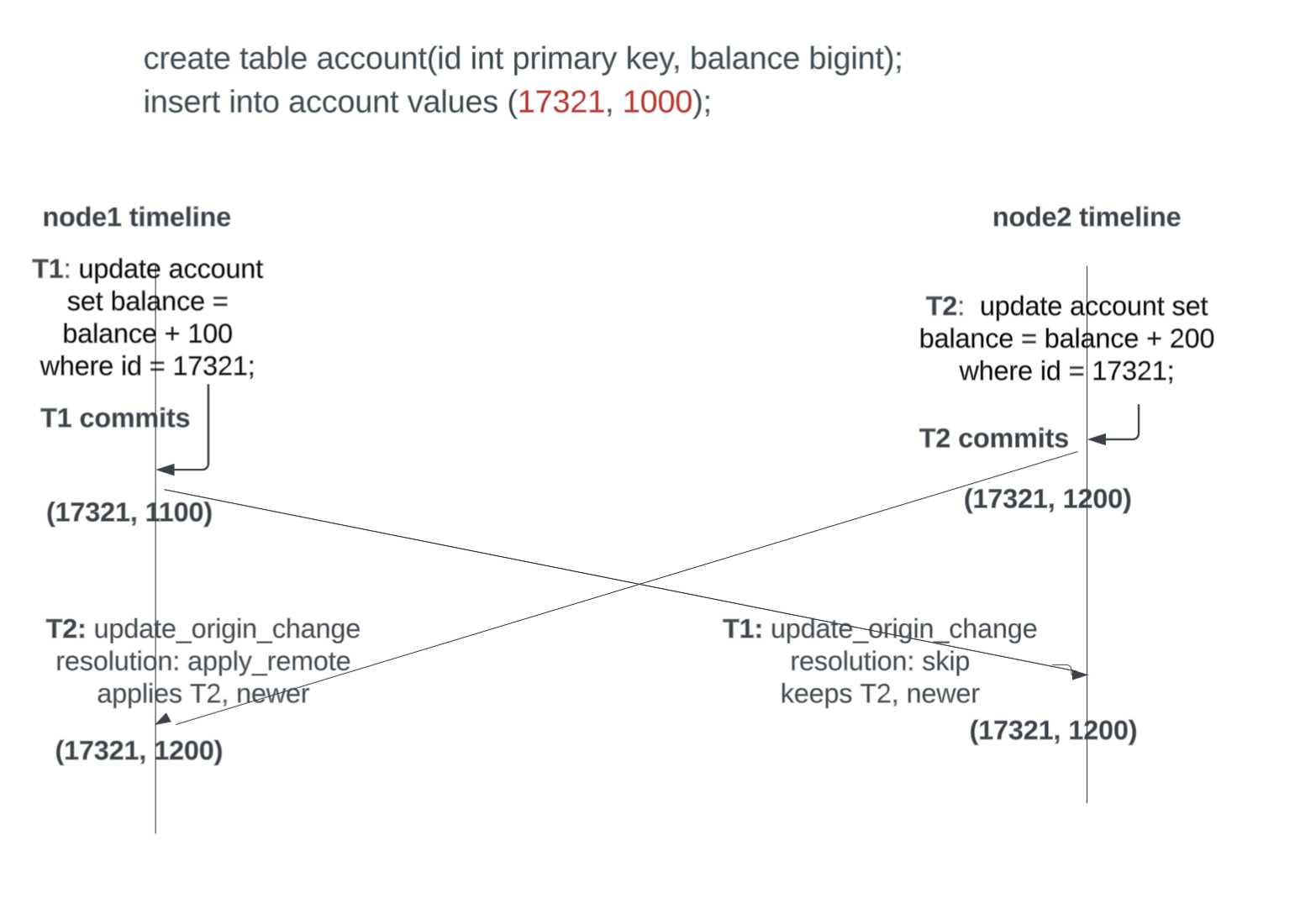
node1 and node2 get T1 and T2 almost concurrently. This can happen when the write leader switches from node1 to node2. node2 commits T2. But shortly after committing T2, it gets T1 when node1 comes up after a crash or the cluster recovers from a network partition.
Value on node2 will be:
<17321, 1200> and it receives an update from node1 with <17321, 1100>
It detects a change of origin - the tuple seen on node2 is written by origin “node2” and tuple that is coming in remotely is from origin “node1”. Not all origin changes can be flagged as conflicts. The real question is: has the remote (“node1”) seen the local row (local node being “node2”). If yes, it means the updates did not cross each other and this is not a conflict. PGD tries to make a determination of this. This works, if the gap between T1 and T2 is high, say more than a minute or so. But it may not always be able to and this is flagged as a conflict. If it is decided that this is a conflict, the code will choose the latest timestamp out of the two tuples and it will apply that change. Depending on which tuple has the latest timestamp the resolution will be apply_remote or skip on that node. And the conflict will be logged. In this case, assuming T1 has an older timestamp, the final value will be 1200. This is the last-writer-wins strategy. As can be seen from this example, this results in a lost update. (To avoid lost updates, consider the use of CRDTs or eager conflict resolution with Group Commit.)
But the more important goal is to not let the data diverge across replicas. All replicas will make the same decision, so there is no data divergence.
Clock-skew can change this. Consider the same situation as above. But the time on node1 is somewhat ahead of node2.

node1 first commits T1, and node2 receives T1 first. It then gets T2 and commits it, so the final value of the row is <17321, 1300>. When T2 goes to node1, it is flagged as an origin_change_conflict, and node1 chooses T1 over T2 due to the timestamp of T1 being higher, so at that point the value of balance is 1100. This on node1, the balance is 1100 and on node2 it is 1300. Thus data diverges. The problem is that on node2, a transaction from the future (T1) was allowed to commit, thereby allowing T3 to overwrite it. There are a few ways this can be avoided. This is discussed in the section on Avoidance of Conflicts.
update_missing
This conflict can occur in a few cases.
update and insert crossing each other
Consider 3 nodes.
- node1 inserts A and crashes.
- Soon after, node2 became the write leader. It sees the insert and updates it to A1.
- On node3, insert and update can occur in any order, based on delays in either subscription. It is possible node1 could not send it A before crashing. Therefore, it would get the update first. It will note the conflict as update_missing but will continue with default resolution of apply_remote to upsert A1 directly (insert the updated tuple as A1), since update gets the full new tuple.
- It may get the insert later, in which case it also logs a conflict of insert_exists, with a default resolution of update_if_newer.
- It is to be noted that since update on one node saw the insert, it is likely to have higher timestamp, but if node2 is behind due to clock skew, then it may have a lower timestamp. On node3, update_if_newer can possibly update the newer update with the older insert. And cause data divergence. This case is similar to the one discussed above with update_origin_change conflict and can be fixed in a similar fashion as described in the section on Avoidance of Conflicts.
update and delete crossing each other
Consider another case of say 2 nodes and an update and delete crossing each other.
- node1 deletes A.
- node2 more or less concurrently updates A to A1 which succeeds locally because it did not yet get the update.
- node1 on getting the update from node2, tries to find the tuple, even a tuple deleted in the past.
- If a previously deleted tuple is found, we mark conflict as update_recently_deleted and skip the update.
Also, on node2 on getting the delete from node1 will delete the tuple. The data on all nodes is consistent.
- However, in step d, if the tuple cannot be found by node1, as can happen if it has been pruned away or vacuumed, it will not know that this has been deleted and thinks of the conflict as update_missing, unable to distinguish it from case 1 above and does an apply_remote.
- node2 gets the delete, and deletes the tuple. This can cause data divergence if the tuple is not found.


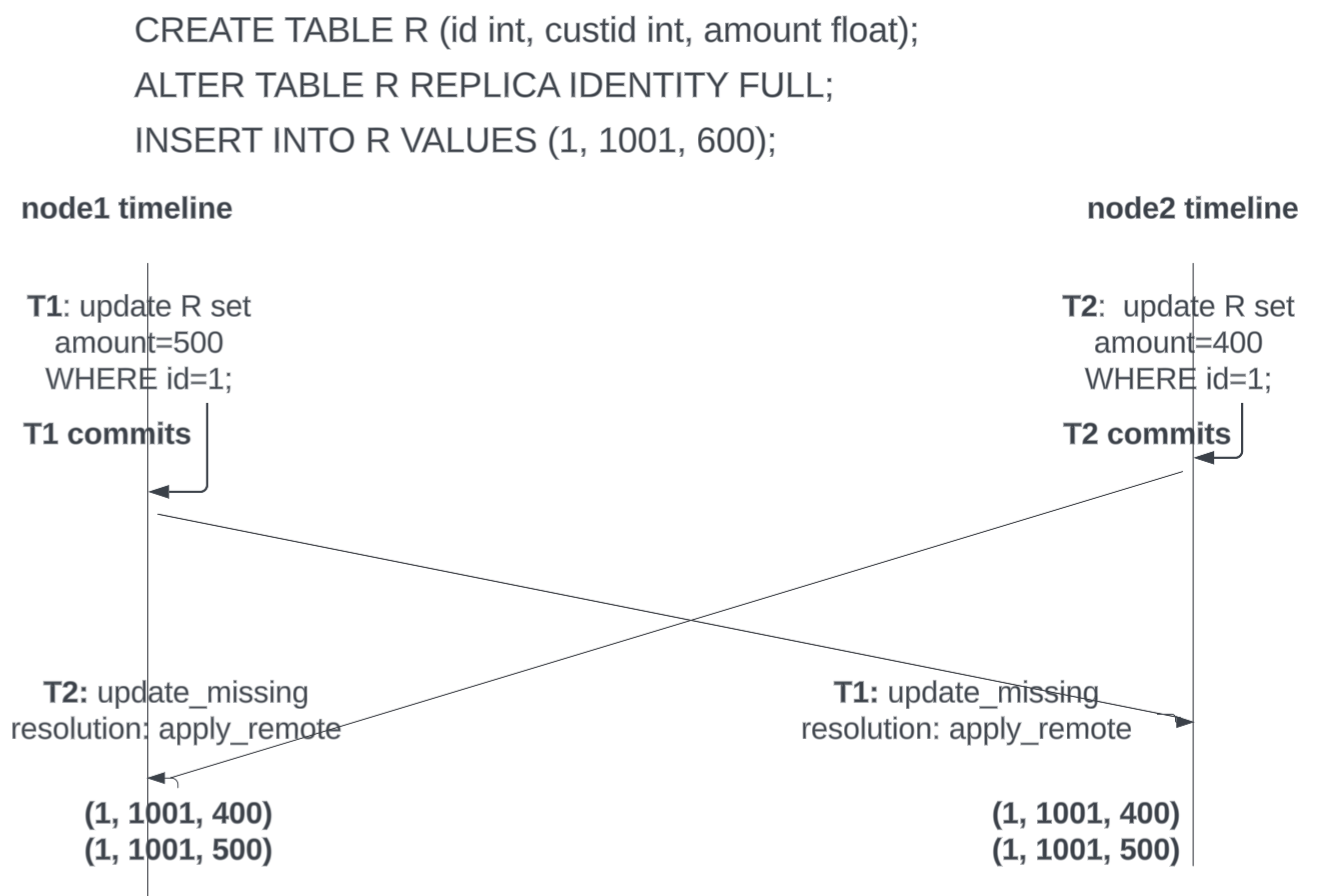
update_missing on a table without unique constraint
This conflict can also occur for a table without any unique constraint with REPLICA IDENTITY FULL. If a row is updated concurrently from two nodes, the downstream receives both the old and new version of the tuple that is updated. It looks for the old version, but that was updated locally, so it is not found and the conflict reported on all nodes is update_missing. The result is apply_remote. So both updates will get applied.
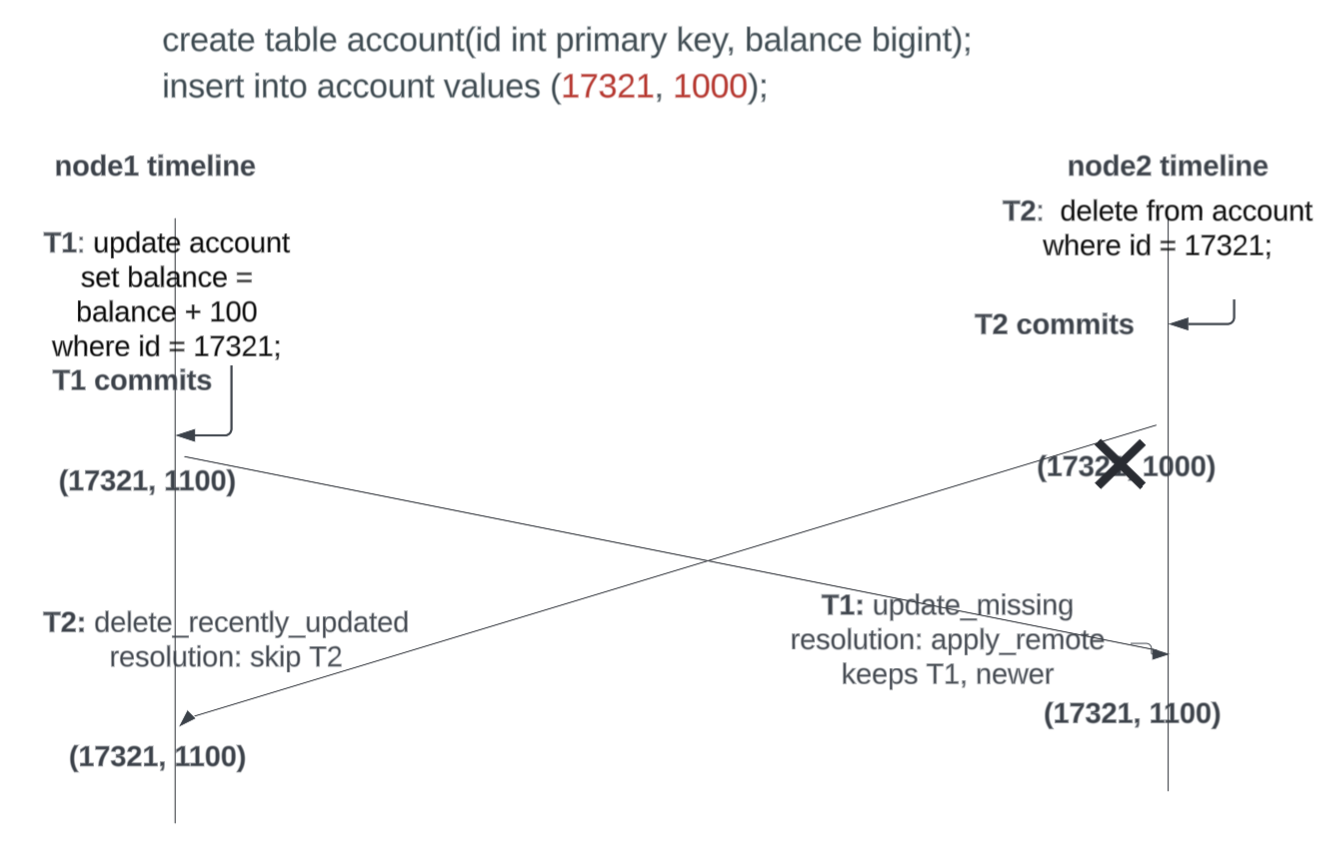
delete_recently_updated
This is similar to update_recently_deleted conflict, except that the delete has an older timestamp. In this case too the resolution is to simply skip the delete, since an update was made later.
update_pkey_exists
This conflict occurs when there is a primary key update, and the new primary key that is being set already exists on the replica. This can happen when two such updates on two nodes cross each other. In this case, the last-writer-wins strategy is chosen and the newest timestamp wins. So the update with the newest timestamp is kept.
delete_missing
This is a conflict that comes when two nodes delete a row concurrently. When the transaction is replicated, it does not find the row. The resolution is skip, which means this condition is ignored.
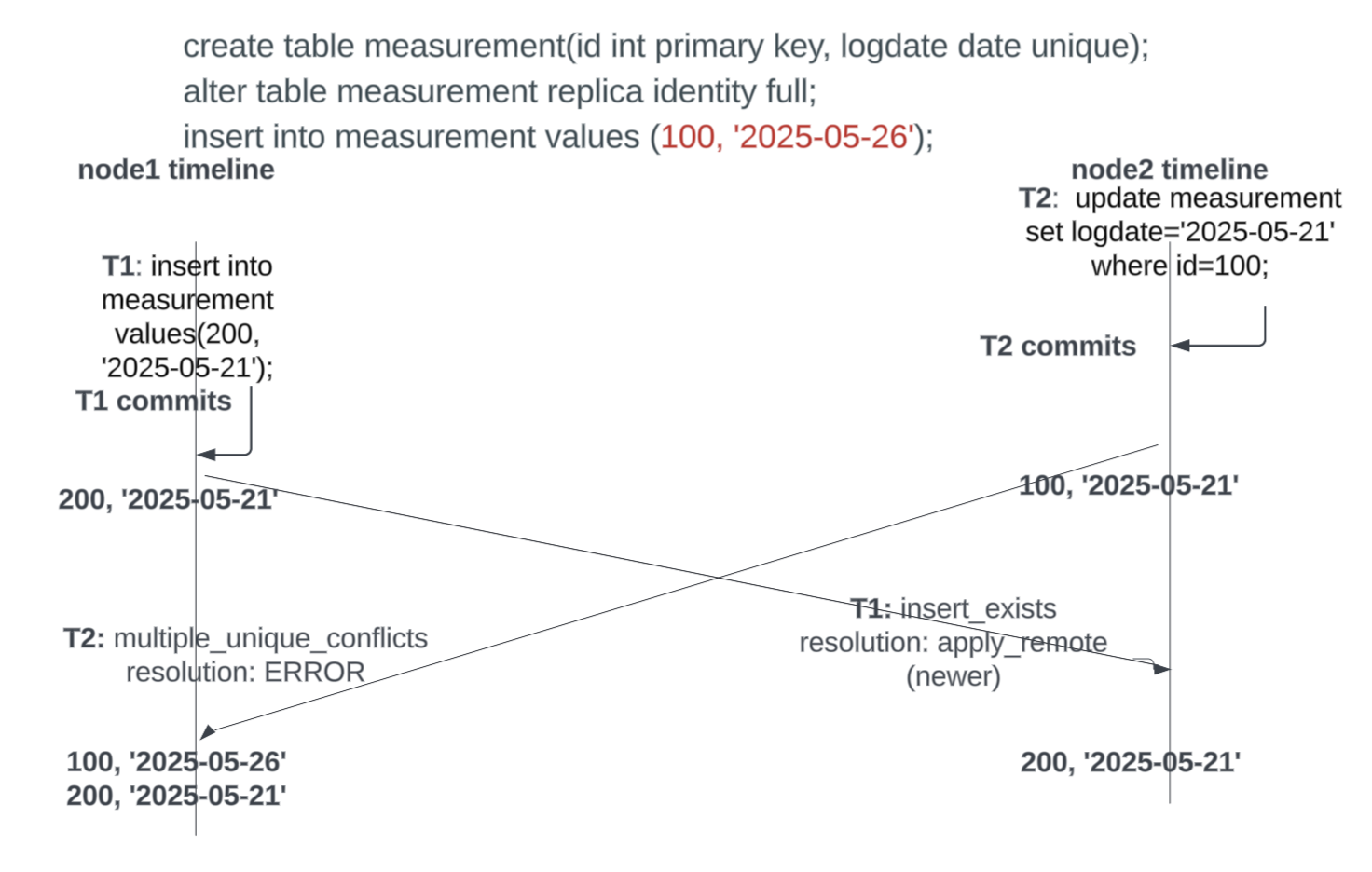
multiple_unique_conflicts
This is caused due to a conflict between an insert and an update when there is a clash with an index other than the primary key. If only primary key clashes, conflict is categorized under update_pkey_exists. If two updates clash, the conflict comes under update_origin_change. The challenge with this conflict is that the conflicting statements are NOT referring to the same row, as happens with all other conflict types. Therefore, it is not possible to make a decision such as discarding one vs the other, as can be done with other conflict types. The resolution is rather tricky, and therefore the writers ERROR out giving information about the conflict, so the user can manually resolve it. Consider the following example.
Avoidance of Conflicts
Conflicts coming due to clock skew can be avoided with one of the following techniques.
- Do not let a node apply a commit from the future from another node. This may come at the cost of some performance. Essentially, we are making a transaction with a future timestamp wait till it applies. The following settings do this.
ALTER SYSTEM SET bdr.maximum_clock_skew = 0;
ALTER SYSTEM SET bdr.maximum_clock_skew_action = 'wait';
SELECT pg_reload_conf();- Data divergence will typically only occur if clock skew is greater than the time it takes to change write leader since the commit timestamps of two updates would differ by at least that much time. By monitoring clock skew on PGD nodes, it can be ensured that this does not happen.
- Row-version conflict detection when used with REPLICA IDENTITY FULL can avoid this. With this, the data divergence with clock-skew does not happen. Nor are there any false positives with conflict detection. The resolution continues to use last-update-wins strategy. So there can be lost updates.
- In addition, following these guidelines help in reducing conflicts with PGD.