What is pgvector, and How Can It Help Your Vector Database?

There are countless ways to accelerate Postgres workloads. It’s all in how you store and query data, how big your data is, and how often you run those queries.
In this blog post, we’ll explore how pgvector can help with AI-based workloads in Postgres, making your database vector operations faster and more efficient.
pgvector: Storing and Querying Vector Data in Postgres
pgvector is a PostgreSQL extension that allows you to store, query, and index vectors.
Postgres does not have native vector capabilities as of Postgres 16, and postgres pgvector is designed to fill this gap. You can store your vector data with the rest of your data in Postgres, do a vector similarity search, and still utilize all of Postgres’ great features.
Who Needs Vector Similarity Search?
When working with high-dimensional data, especially in applications like recommendation engines, image search, and natural language processing, vector similarity search is critical. Many AI applications involve finding similar items or recommendations based on user behavior or content similarity. pgvector can perform vector similarity searches efficiently, making it suitable for recommendation systems, content-based filtering, and similarity-based AI tasks.
The pgvector extension integrates seamlessly with Postgres – allowing users to leverage its capabilities within their existing database infrastructure. This simplifies the deployment and management of AI applications, as there's no need for separate data stores or complex data transfer processes.
What is a Vector Exactly?
Vectors are lists of numbers. If you have taken a linear algebra course, this is the time to reap the benefits, as similarity search is doing many vector operations!
In geometry, a vector represents a coordinate in an n-dimensional space, where n is the number of dimensions. In the image below, there is a two-dimensional vector (n=2). In machine learning, we use high-dimensional vectors, which are not as easy to imagine as the simple vector shown below.
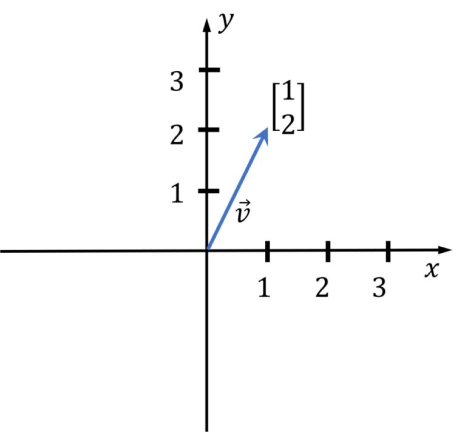
Image source: https://media5.datahacker.rs/2020/03/Picture36-1-768x712.jpg
Step-by-Step pgvector Tutorial
In this example, we will store a few documents, generate postgres embeddings, and store these embeddings. We will index the embeddings data and run a similarity query on them.
Here’s the code for the example we’re discussing here: https://github.com/gulcin/pgvector_blog
Prerequisites:
- PostgreSQL installed (pgvector supports PostgreSQL 11+)
- pgvector extension installed (see installation notes)
- OpenAPI account and have some credit balance (uses less than $1).
Once pgvector is installed, you can enable it in your Postgres database by creating the extension:
postgres=# Create extension vector;
CREATE EXTENSIONStep 1: Create a table for documents
Let’s create a simple table to store documents. Each row in this table represents a document, and we store the title and content of the document.
Create documents table:
CREATE TABLE documents (
id int PRIMARY KEY,
title text NOT NULL,
content TEXT NOT NULL
);We will generate an embedding for each document we store and create a document_embeddings table to store them. You can see the embedding vector has a size of 1536 because the OpenAI model we are using has 1,536 dimensions.
-- Create document_embeddings table
CREATE TABLE document_embeddings (
id int PRIMARY KEY,
embedding vector(1536) NOT NULL
);Let’s index our data using the HNSW index.
CREATE INDEX document_embeddings_embedding_idx ON document_embeddings USING hnsw (embedding vector_l2_ops);I will discuss indexing in vector databases in my next blog post, so I won’t go into much detail here, but we know HNSW has better query performance than IVFFlat.
Also, for IVFFlat indexes, it is best to create the index after the table has some data. For HNSW indexes, there is no training step like with IVFFlat, so the index can be made without any data in the table. You might have noticed that I created the index before inserting data into the table, following the suggestion.
Now, we can insert some sample data into the table. For this example, I chose Postgres extensions and their short descriptions.
-- Insert documents into documents table
INSERT INTO documents VALUES ('1', 'pgvector', 'pgvector is a PostgreSQL extension that provides support for vector similarity search and nearest neighbor search in SQL.');
INSERT INTO documents VALUES ('2', 'pg_similarity', 'pg_similarity is a PostgreSQL extension that provides similarity and distance operators for vector columns.');
INSERT INTO documents VALUES ('3', 'pg_trgm', 'pg_trgm is a PostgreSQL extension that provides functions and operators for determining the similarity of alphanumeric text based on trigram matching.');
INSERT INTO documents VALUES ('4', 'pg_prewarm', 'pg_prewarm is a PostgreSQL extension that provides functions for prewarming relation data into the PostgreSQL buffer cache.');Step 2: Generate embeddings
Now that our documents are stored, we will use an embedding model to convert them into embeddings.
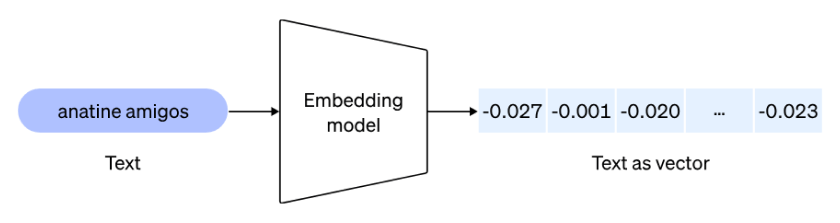
Image source: https://cdn.openai.com/new-and-improved-embedding-model/draft-20221214a/vectors-1.svg
But first, let’s talk about embeddings. I like the definition from OpenAI docs best because it’s simple and on-point:
An embedding is a vector (list) of floating point numbers. The distance between two vectors measures their relatedness. Small distances suggest high relatedness, and large distances suggest low relatedness.
So, if we compare how related two documents are semantically, we would have to transform those documents into embeddings and run similarity searches on them.
You can choose API providers and use these APIs with your preferred language. For its simplicity and prior experience, I picked OpenAI API, with Python as my preferred language. The embedding model used in the example is “text-embedding-ada-002,” which will work well for our use case as it is cheap and simple. You may need to evaluate different models depending on your specific use case in real-world applications.
Let’s start. For the Python code below, you must obtain your OpenAI API key and fill out the connection string to connect to your Postgres database.
# Python code to preprocess and embed documents
import openai
import psycopg2
# Load OpenAI API key
openai.api_key = "sk-..." #YOUR OWN API KEY
# Pick the embedding model
model_id = "text-embedding-ada-002"
# Connect to PostgreSQL database
conn = psycopg2.connect(database="postgres", user="gulcin.jelinek", host="localhost", port="5432")
# Fetch documents from the database
cur = conn.cursor()
cur.execute("SELECT id, content FROM documents")
documents = cur.fetchall()
# Process and store embeddings in the database
for doc_id, doc_content in documents:
embedding = openai.Embedding.create(input=doc_content, model=model_id)['data'][0]['embedding']
cur.execute("INSERT INTO document_embeddings (id, embedding) VALUES (%s, %s);", (doc_id, embedding))
conn.commit()
# Commit and close the database connection
conn.commit()This code fetches document contents from the database, uses OpenAI API to generate embeddings, and then stores these embeddings back in the database. While this works for our small database, in a real-world scenario, you would want to use batching on existing data and an event trigger, or change streaming to keep the vectors up to date as the database changes.
Step 3: Querying embeddings
Now that we have stored embeddings in the database, we can query them using pgvector.
The code below shows how to perform a similarity search to find documents similar to a given query document.
# Python code to preprocess and embed documents
import psycopg2
# Connect to PostgreSQL database
conn = psycopg2.connect(database="postgres", user="gulcin.jelinek", host="localhost", port="5432")
cur = conn.cursor()
# Fetch extensions that are similar to pgvector based on their descriptions
query = """
WITH pgv AS (
SELECT embedding
FROM document_embeddings JOIN documents USING (id)
WHERE title = 'pgvector'
)
SELECT title, content
FROM document_embeddings
JOIN documents USING (id)
WHERE embedding <-> (SELECT embedding FROM pgv) < 0.5;"""
cur.execute(query)
# Fetch results
results = cur.fetchall()
# Print results in a nice format
for doc_title, doc_content in results:
print(f"Document title: {doc_title}")
print(f"Document text: {doc_content}")
print()The query first fetches an embeddings vector for the document titled “pgvector” and then uses the similarity search to get documents with similar content. Note the “<->” operator: that’s where all the pgvector magic happens. It’s how we get the similarity between two vectors using our HNSW index. The “0.5” is a similarity threshold that will be highly dependent on the use case and requires fine-tuning in real-world applications.
Results
When we ran our query script on the data we imported, we saw that the similarity search found two documents similar to pgvector, one of them being the pgvector itself.
❯ python3 query.py
Document title: pgvector
Document text: pgvector is a PostgreSQL extension that provides support for vector similarity search and nearest neighbor search in SQL.
Document title: pg_similarity
Document text: pg_similarity is a PostgreSQL extension that provides similarity and distance operators for vector columns.EDB Postgres® AI Cloud Service Now Supports pgvector
Postgres® AI Cloud Service is EDB’s managed Postgres service that allows you to run Postgres on all major cloud platforms. Now, you can enable pgvector on your databases and start experimenting!
Start your free trial on Postgres® AI Cloud Service today with $300 in free credits!
pgvector: FAQs
pgvector is an extension for Postgres that enables efficient storage and similarity search of high-dimensional vector data, commonly used for machine learning models, recommendation systems, and natural language processing applications.
pgvector extends Postgres to support vector data types. Vectors represent entities like text or images as points in high-dimensional space. This allows for the calculation of distances between points and the determination of similarity in unrelated data.
Pgvector offers significant scalability, especially when paired with the pgvectorscale extension for large-scale vector workloads. PostgreSQL with pgvector and the pgvectorscale extension can handle datasets as large as 50 million high-dimensional vectors.
Consider the type of data you need to manage, how your project may need to scale, how pgvector will integrate with your existing tech stack, pgvector’s performance characteristics, and your organization’s budget.
pgvector is mainly used for natural language processing such as sentiment analysis and document classification, recommendation systems such as product suggestion systems for retailers, image search and recognition such as reverse image search and object recognition for fashion sites, and anomaly detection for financial institutions.
Yes. It allows for combining traditional keyword search with vector similarity search.
Yes. Cosine similarity is a core distance metric for vector similarity searches. It allows users to assess the similarity between two vectors based on the cosine of the angle between them. This useful when these vectors’ directional alignment is the primary concern.
pgvector on EDB Postgres AI unifies AI, transactional, and analytical workloads in a single, secure platform, delivering 4.22X faster queries, 5X smaller disk footprint, and 18X storage cost efficiency vs. basic Postgres while leveraging enterprise-grade features for seamless integration, rapid development, and future-proof scalability.
The single-database approach simplifies development, accelerates time-to-market, and reduces infrastructure costs. Customers benefit from a mature, enterprise-grade platform that evolves with their AI needs, avoiding the complexities and limitations of multi-database solutions.
Enterprise customers seeking to implement AI workloads often turn to specialized vector databases that lack scalability and performance for large-scale use and come with steep learning curves. They can create data silos, vendor lock-in, and security concerns.