The Life of a Bug: From Customer Escalation to PostgreSQL commit

In the intricate world of software development, bugs are the elusive creatures that can disrupt the smooth operation of applications and systems. At times my co-journey with a bug begins with a customer escalation, setting off a series of events leading to investigation, resolution, and ultimately, a more robust software ecosystem. Let's delve into the life of one such bug, tracing its path from customer escalation to a patch release and ultimately the redesign of a critical Postgres subsystem.
The Awakening: Customer Escalation
The bug's journey begins when a support ticket is escalated to our engineering team for Postgres development, signaling a critical issue that threatens the stability of their banking service due to an overwhelming load on the database server.
This marked my introduction to this issue in a customer call concerning this issue, alongside the support team members. It became evident that the server was so overloaded that it could not accept new connections.
Discovery and Reporting
As a PostgreSQL developer in such cases, my first step was to identify the wait event on which the system was spending most of its time.
- We executed the below query on the problematic server and aggregated the results based on the wait_event
\t
select wait_event_type, wait_event from pg_stat_activity where pid != pg_backend_pid()
\watch 0.5 - And observed the aggregated wait event as shown in the below table
| Count | wait_event_type | wait_event |
|---|---|---|
| 86595 | LWLock | SubtransSLRU |
| 14619 | LWLock | SubtransBuffer |
| 2574 | Client | ClientRead |
| 1876 | Activity | WalWriterMain |
| 823 | ||
| 404 | IO | SLRURead |
The empty wait_event means the actual work done on the CPU without waiting on anything, so here we can observe the system is taking 100X more time waiting on SubtransSLRU and SubtransBuffer wait_events.
Investigation and Analysis
The SubtransSLRU and SubtransBuffer wait events in PostgreSQL typically arise during periods of heavy load on the pg_subtrans SLRU subsystem. The SLRU (Simple Least Recently Used) cache is a mechanism backed by disk pages that stores various transaction-related information crucial for PostgreSQL's operation.
To delve deeper into this issue, it's essential to understand the concept of visibility in PostgreSQL and how it relates to these wait events. The visibility of a tuple, or row version, is determined by the xmin and xmax system columns, which hold the transaction IDs of the creating and deleting transactions respectively. When a query starts, PostgreSQL creates a snapshot that dictates the visibility rules throughout the query's execution. This snapshot comprises an array of concurrent transactions and subtransactions.
Initially, PostgreSQL prepares by examining the shared data structure and reading the transaction ID of each session. However, since multiple subtransactions can exist under a single transaction, PostgreSQL limits the cache to 64 subtransactions per top transaction. If a transaction surpasses this limit and creates more than 64 subtransactions, it causes an overflow in the cache. As a result, concurrent snapshots lack complete information and are marked as overflown.
When checking the visibility of a transaction in a row, PostgreSQL first retrieves its top transaction ID, necessitating access to the SLRU cache, a simple LRU cache backed by disk storage. As the number of overflown snapshots increases, concurrent backends contend for access to the SLRU cache, leading to the SubtransSLRU lock and associated wait events.
Moreover, in the presence of long-running transactions, PostgreSQL needs to fetch parent information for older subtransactions along with the latest subtransaction. This broadens the scope of the xid lookup, further straining the SLRU cache and resulting in frequent disk page loads and disk I/O operations, as indicated by the SubtransBuffer wait event.
The presence of a subtransaction overflow in the customer environment was evident, but pinpointing the specific part of the application responsible remained uncertain. This ambiguity stemmed from the fact that the performance impact of the subtransaction overflow would not be confined to the backend generating the overflow. Instead, its effects would be observable across all backends. As a result, solely relying on the wait_event and process ID was insufficient to identify the backend causing the overflow because that wait_event will be observed in all the backend getting impacted by the overflow created by one of the backend.
Classification and prioritization
To help identify the queries involved in creating the sub-transaction overflow we provided a custom extension to the customer for regularly monitoring the subtransaction count and subtransaction overflow status by each backend. Later we committed that work in PostgreSQL open source code [1] where we provided a new view pg_stat_get_backend_subxact() for monitoring the subtransaction overflow and count.
Validation and user feedback
With the help of the custom extension users were able to find the problematic application logic which was causing the subtransaction overflow. Although they tried to reduce the number of subtransactions based on the application design there was no way to do this and preserve the fundamental business logic of the application.
Providing Temporary Relief
Given the widespread impact of this issue on the entire business, it was imperative to implement a temporary solution to ensure smooth operations. To address the subtransaction cache overflow, we deployed a hotfix patch that raised the per-session subtransaction cache limit from 64 to 256. This specific number was selected based on the application's maximum usage of subtransactions.
While this adjustment increased the memory footprint of each snapshot and may have led to some performance degradation, it served as an interim measure to prevent the application from being blocked due to subtransaction cache overflow. It's important to note that this hotfix was not considered a final solution, but rather a pragmatic step to maintain business continuity.
This way the customer didn't need to wait until the next Postgres release to have the bug fixed. Also, since we maintained this fix in a private customer release, no other customer had to be concerned about what adverse impact change this constant may have on their application.
Working on the actual problem
Once we had relieved the customer's pain, we started our journey toward solving the long pending performance problem in the Postgres SLRU, which has been problematic for many years and discussed in various blogs [4] there have been multiple attempts to fix that problem but so far no one succeeded in that journey.
I started to analyze the problem in more detail by reproducing this problem locally using the pgbench workload and discussing this in various conferences [2].
From there we started to work on designing the solution for the problem, we also analyzed the past solutions and proposed their benefits and limitations. I picked some of the existing ideas as a base and built a new idea on top of that to completely resolve the problem. I have presented the solution at one of the conferences [3].
I received constant support from the PostgreSQL committers Robert Haas and Alvaro Herrera throughout this work.
Posting the solution and getting it committed
Finally after implementing the solution and after a lot of performance testing and verification in the customer environment, I have posted this solution to the PostgreSQL open-source community [5].
There it went through a lot of design and code changes and finally, Alvaro Herrera committed this solution to the PostgreSQL open source. A detailed blog has been written to elaborate on the problem and the solution we've implemented. I'm glad to share that this solution will be included in Postgres 17 [6].
Performance analysis after the fix
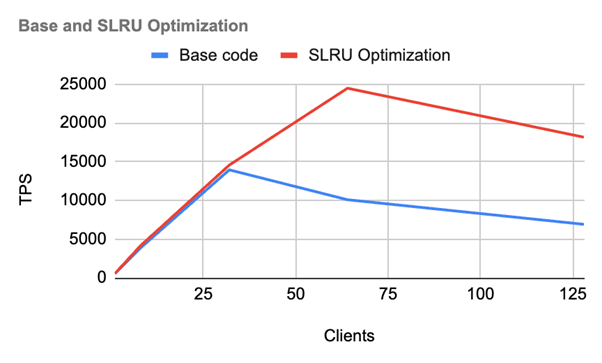
We have compared the performance metrics between the unpatched version and the patched version. It is evident that the performance significantly drops with the base code under high client counts, whereas the patch performs much better. The fixed version runs approximately 2.5-3.0 times faster than the unpatched version.
| Test Machine | Intel 128 core machine 512 GB RAM 8 CPU |
|---|---|
| Test |
|
| Results | We've observed a significant performance drop at 30 clients, but after implementing the solution, the performance scales linearly up to 70 clients. |
Conclusion: Embracing the Bug's Impact
The journey of a bug from support escalation to resolution is a testament to the resilience and adaptability of software development teams. Bugs, while disruptive, serve as catalysts for improvement, innovation, and customer satisfaction. Embracing the impact of bugs fosters a culture of transparency, collaboration, and proactive problem-solving, ultimately leading to more robust, reliable, and user-centric software solutions.
Although this was a long pending issue in open source software when this problem was impacting our customers we put all our effort into analyzing the issue, presenting it in different forums to attract more attention, and finally fixing it as a community.
Reference
[1] https://www.postgresql.org/message-id/E1p7MF8-004RLt-5L%40gemulon.postgresql.org
[2] https://www.youtube.com/watch?v=RUtVaIjrxOg&t=1384s
[3] https://www.youtube.com/watch?v=9ya08Q278pg
[4] https://postgres.ai/blog/20210831-postgresql-subtransactions-considered-harmful
[5] https://www.postgresql.org/message-id/CAFiTN-vzDvNz%3DExGXz6gdyjtzGixKSqs0mKHMmaQ8sOSEFZ33A%40mail.gmail.com
[6] https://pganalyze.com/blog/5mins-postgres-17-configurable-slru-cache