Why Your Analytical Database Needs Multiple Clusters to Do What WarehousePG Does With One

This blog is co-authored by Jack Christie and Dave Stone. It was updated with new insights on March 31, 2026.
When Querying Business Data Becomes a Budget Problem
"We have been plagued by runaway costs for querying our 50TB cloud data warehouse."
That's Mr. Jung, Heung Sik, Head of IT Support at Kyobo Book Centre (South Korea's largest bookstore chain) describing a problem that's become increasingly common: the consumption-based pricing model that made cloud data warehouses attractive for data engineering and scheduled analytics creates unpredictable costs when you have high-concurrency BI workloads with hundreds of business users simultaneously refreshing dashboards, drilling into reports, and triggering real-time queries.
Kyobo had 50TB of business data and growing, a small analytics team supporting Tableau users, and years remaining on their cloud data warehouse contract. Every dashboard refresh generated charges. Every analyst query added to the bill. Performance required constant optimization, and the team was spending more time managing costs than delivering insights.
They couldn't migrate because they were contractually committed. But they also couldn't sustain the economics of consumption-based compute for high-concurrency analytics workloads.
The Concurrency Challenge: Why BI Workloads Scale Differently
Cloud data warehouses excel at what they were designed for: large-scale data engineering and scheduled analytical workloads. The consumption model makes sense when you're running periodic ETL jobs or training ML models. You use resources, then they scale down.
The Modern Pace of Business Intelligence
Modern analytics is different. You have business users refreshing dashboards throughout the day. Data scientists running exploratory queries. Financial analysts generating reports. AI agents providing conversational analytics insights. All simultaneously.
This is where the architectural choices behind modern cloud platforms create challenges. An analysis by Principal Architect Nick Akincilar tested how platforms handle concurrent BI users running hundreds of unique queries against a multi-billion row dataset (a realistic enterprise scenario).
The results showed significant differences in how platforms manage concurrency:
- Resource scaling varied dramatically, with some platforms spinning up 5 clusters while others needed only 2 for the same workload
- Queue times ranged from near-instant to 30+ seconds as platforms decided how to allocate resources
- Query failure rates in some cases reached nearly 4% due to connection management issues
- Cost differences of 73% for identical workloads based purely on how platforms auto-scale
As Akincilar observed: "Nothing like trying to save $1 on data engineering to spend $4 extra on consumption and have business complaining about their dashboards."
Why Concurrency Matters for the AI Generation
When we talk about modern analytics, nothing comes to mind faster than agentic analytics: autonomous AI agents querying analytical databases just like a human. This puts even more concurrent load on the warehouse, and it’s not just straightforward user growth.
Think of each agent as a superhuman user, writing and executing hundreds of queries in a matter of seconds, then evaluating to determine if more queries are required to complete their goals. Even if cloud data warehouses could keep up, the budget would explode before performance even had a chance to tank.
This dynamic was front and center at NVIDIA GTC 2026, where the theme of data as the ground truth for AI dominated conversations. The consensus was clear: as enterprises move from isolated agentic experiments to agentic workforces — autonomous agents reasoning and acting across massive volumes of live enterprise data — the data infrastructure underneath becomes the difference between experimentation and scale. EDB's own Sovereignty Matters research found that only 13% of enterprises have managed to cross into production-scale agentic deployments with more than 10 active workflows. Those that have are getting 5x higher ROI and operate with twice the agent density per business process. The bottleneck isn't the models. It's the data.
Why Architecture Matters for Concurrent Workloads
Modern cloud data warehouses were built for elastic workloads (those unpredictable spikes where you suddenly need 10x the compute, then scale back down an hour later). They handle this by spinning up additional clusters when demand increases, then billing you for what you used.
This works beautifully for data engineering: batch jobs that run at 2 AM, ML training that happens weekly, ETL pipelines that spike and finish. Variable work deserves variable pricing.
But BI workloads aren't variable. They’re predictable, even with agents.
While agentic analytics introduces a stream of unpredictable queries, the overall BI workload pattern is still highly predictable. You know roughly how many analysts and agents will be querying data during business hours. Elastic pricing is optimized for unpredictable peaks in demand (a huge, temporary spike), whereas AI agents represent a predictable, sustained increase in the baseline concurrency.
The problem: when platforms designed for variable workloads meet predictable concurrency patterns, you get unpredictable costs. More users means more clusters means higher bills, even though your actual usage pattern hasn't changed, just the number of people accessing data simultaneously.
McKnight Consulting Group's February 2026 benchmark report puts a number on this: when Snowflake scales to three multi-clusters to handle peak concurrency, annual costs reach $351,953 — 58% more than WarehousePG's $222,886 for the same business analytics workloads. The equation is simple: elastic infrastructure creates elastic costs. For workloads that aren't actually elastic, that's a mismatch.
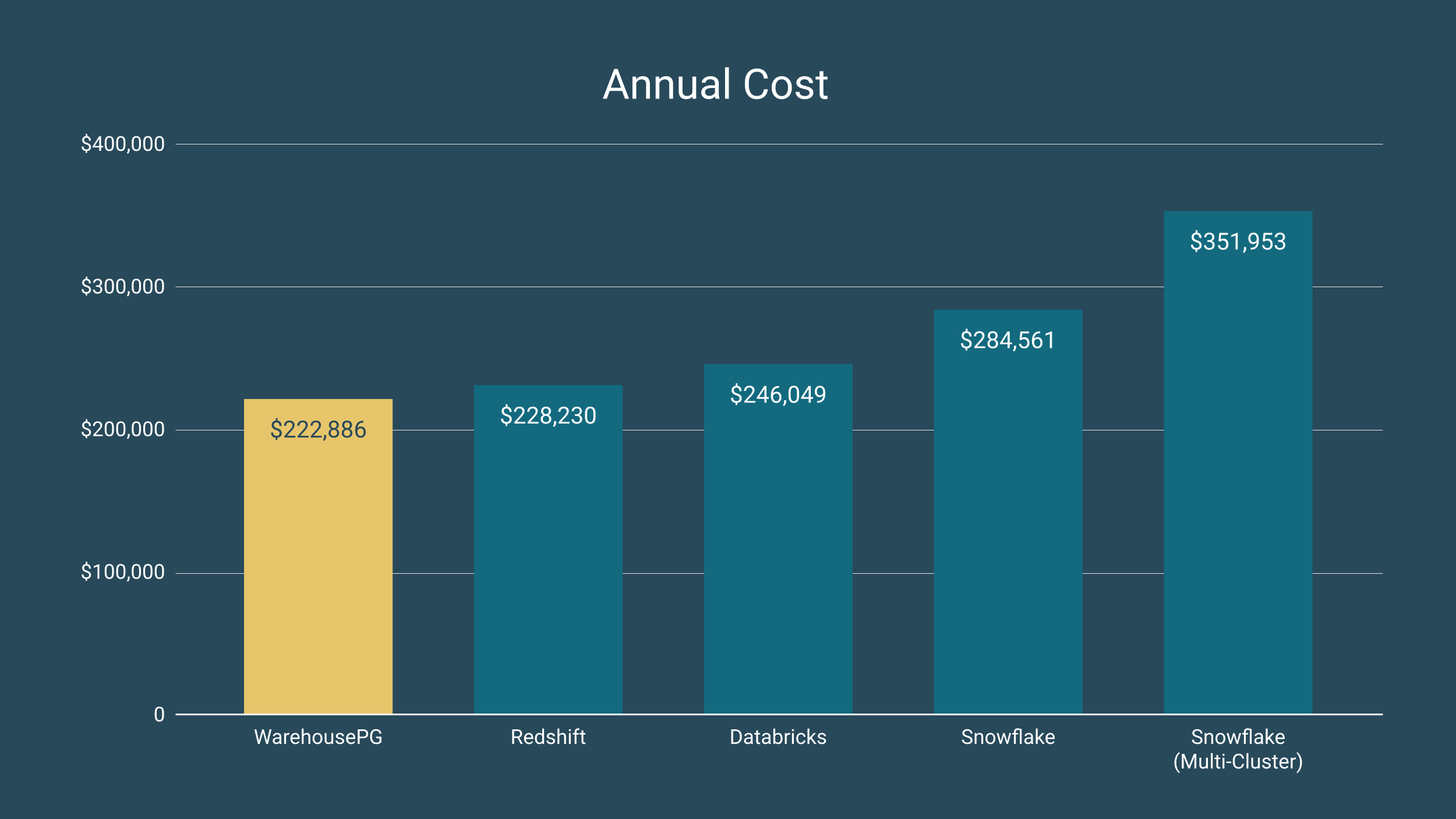
The Postgres Alternative: Predictable Performance, Predictable Costs
Postgres-based data warehouses take a fundamentally different approach. Built on MPP (Massively Parallel Processing) architecture with decades of proven technology, these platforms handle concurrent workloads without requiring multiple cluster orchestration.
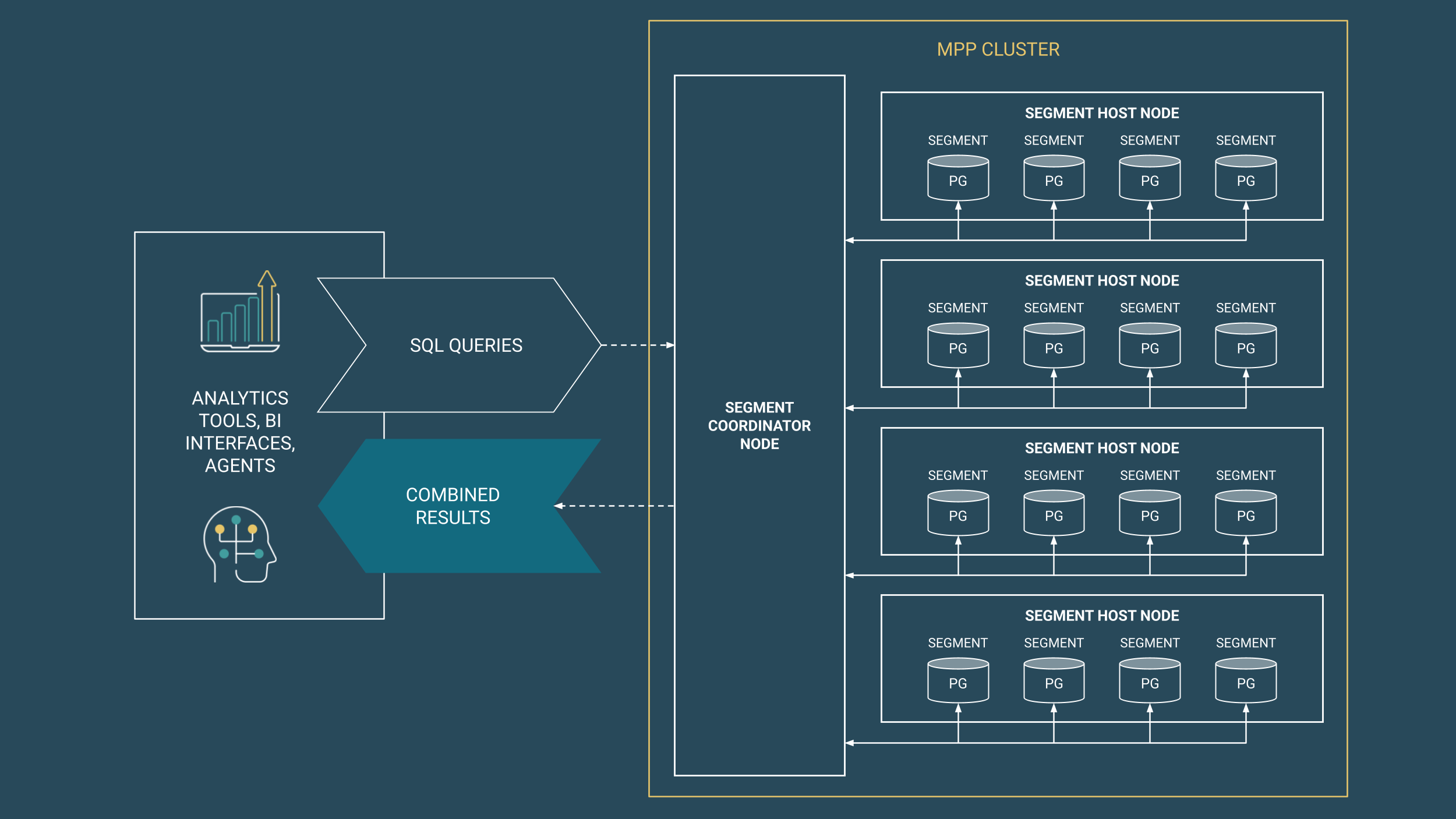
Independent benchmark testing by McKnight Consulting Group (February 2026) tested WarehousePG against Snowflake, Databricks, Redshift, and Hive on Apache Iceberg across concurrency and mixed workloads on a 10TB TPC-DS dataset — the industry standard for real-world analytical workload simulation. The results are compelling.
On concurrency, WarehousePG showed the lowest performance slowdown when scaling from one to five concurrent users (2.7x), compared to Snowflake (3.9x), Redshift (4.0x), and Databricks (4.1x). That lower slowdown factor translates directly to a more consistent, predictable user experience as analyst and agent workloads grow. Download the full McKnight Consulting Group benchmark report to see the complete methodology and findings.
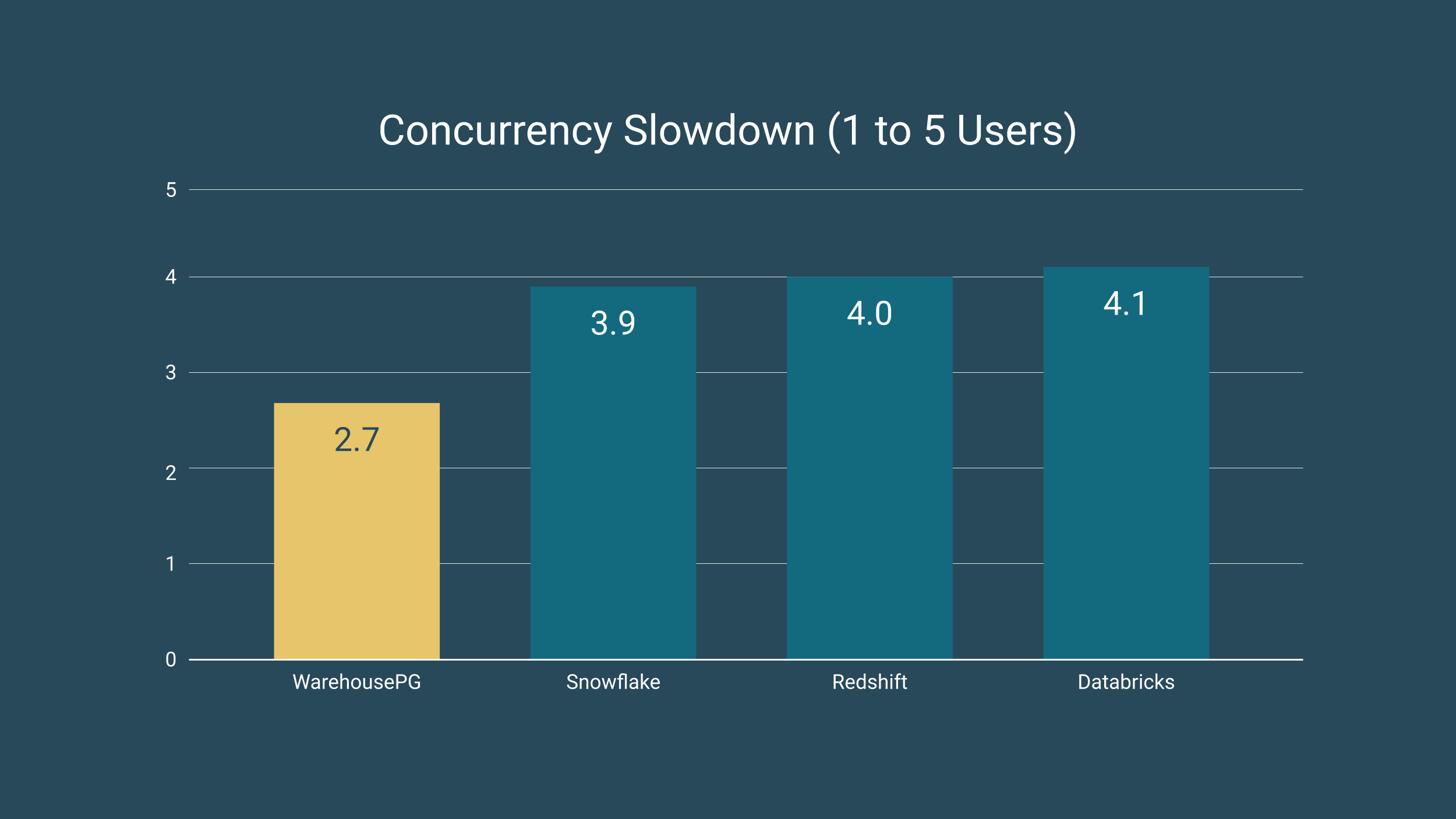
For mission-critical operations, this stability matters. MNTN, a leading connected TV ad-tech platform managing petabyte-scale data, has been using Postgres-based data warehouses for years. They’ve always been happy with performance, but needed an open source alternative and an enterprise partner to guarantee operational uptime and responsive support. EDB Postgres AI for WarehousePG was their solution. As Greg Spiegelberg, Head of Data at MNTN, put it: "The performance is there, the stability is there, the support is responsive as they should be. I'm just happy that there's somebody there that can be with me in the middle of the night and I'm not, quite literally, hacking open-source code trying to get the database recovered."
Simple Beats Complex for Known Workloads
When you know you'll have consistent BI workloads (daily dashboard refreshes, regular reporting cycles, predictable analyst queries), the path forward doesn't require a high-risk infrastructure replacement.
The difference comes down to predictability:
Consumption-based platforms optimize for variable workloads. You pay for what you use, but "what you use" depends on hidden variables: how aggressively the platform auto-scales, how long clusters stay warm, whether queries queue or execute immediately, and how many clusters spawn to handle concurrent demand.
Capacity-based platforms optimize for known workloads. You provision cores based on your concurrency needs and pay the same amount whether you run 1,000 queries or 100,000. When platforms need to spin up 3-5 additional clusters to handle peak concurrency, your capacity-based costs remain flat. For organizations with established BI workloads (which is most enterprises), predictability often matters more than elasticity.
The McKnight report introduces a useful framing here: the "Flexibility Tax." As enterprises simplify their stacks and bring warehouses into their data and AI platforms, the cost of maintaining a fragmented, best-of-breed stack increasingly outweighs the insight it provides. As agentic workloads proliferate, this tax compounds — what the report calls a "broken meter" effect where expanding user bases and AI agents don't just raise your invoice, they create a performance ceiling that forces teams to ration analysis to avoid financial volatility.
Making the transition doesn't mean ripping out your existing infrastructure. Because WarehousePG is rooted in Postgres, teams can leverage familiar SQL skills immediately. For organizations already running Greenplum, the transition is a zero-migration binary swap that can be done in hours, not months.
Euronext FX, a leading pan-European market infrastructure, made exactly this transition to eliminate vendor lock-in with their existing Greenplum deployments. As Grigoriy Zeleniy, Global CTO at Euronext FX, explained: "We're excited to be working with EDB Postgres AI. Its support for Greenplum Workloads is helping us maintain control of where and how we deploy open source software." WarehousePG delivered a seamless binary swap that provided superior enterprise support and open source control across their four global data centers.
In an era of GDPR, data residency requirements, and increasing regulatory scrutiny, this control matters. Organizations need to know exactly where their data resides and who has access, without sacrificing performance or predictability.
Beyond cost predictability, you can run high-volume reporting and BI workloads with confidence — workload management prioritizes critical queries so your most important work always gets through. Native vector capabilities via pgvector let you do AI feature engineering and model training directly on your data without moving it to separate infrastructure. You can ingest and analyze real-time logs and events as they stream in. And with federated queries across data lakes, you can break down data silos without building complex ETL pipelines.
The Path Forward
If you're experiencing unpredictable costs under concurrent BI workloads, you're not alone. The consumption model that made cloud data warehouses attractive for data engineering creates different economics for business intelligence.
You have options:
- Optimize your current platform (implement workload management, tune auto-scaling policies, monitor consumption patterns)
- Accept variable costs as the price of cloud elasticity
- Consider whether capacity-based pricing on proven architecture might better match your workload patterns
Kyobo Book Centre chose the third path. They implemented a hybrid approach: data remains in their existing cloud platform within their VPC (maintaining data sovereignty and contract compliance), but analytics queries route through EDB Postgres AI for WarehousePG (a Postgres-based MPP engine with per-core pricing).
The results:
- Predictable costs: Per-core pricing instead of consumption charges
- Simplified operations: Their small team manages fewer moving parts
- Better performance: Direct Tableau connectivity without extraction workflows
- Maintained sovereignty: Data stays in their VPC, meeting regulatory requirements
- AI-ready foundation: The modernized platform is designed to grow into AI and vector-driven services, including personalized customer experiences powered by EDB Postgres AI’s agentic capabilities
The question isn't whether modern cloud platforms can scale (they absolutely can). The question is whether you're paying for multiple clusters and elastic scaling when what you actually need is predictable performance at predictable cost.
The McKnight report makes the trade-offs concrete: WarehousePG delivers the lowest concurrency slowdown and one of the lowest total cost profiles of any platform tested, while cloud platforms offer maximum throughput for the most demanding, complex analytical workloads. The right answer for most enterprises is a hybrid — cloud-native for high-scale data science and exploratory analytics, WarehousePG for the always-on, high-concurrency BI workloads that power daily operations.
Explore EDB Postgres AI for WarehousePG to learn more about how Postgres-based analytics handles high-concurrency workloads with cost predictability, or contact our team for a workload assessment.