CloudNativePG Tutorial: Manage Multiple Cloud-Native Databases

Streamline database management with CloudNativePG on Kubernetes
Let’s face it: Kubernetes is taking over the internet. Whether it be a complex app stack full of microservices, to the latest “serverless” API, it’s a great universal platform for deploying fully orchestrated ecosystems. Postgres isn’t necessarily a new resident of this exciting new frontier, but it’s certainly an evolving one. One way or another, that means Postgres DBAs must broaden their horizons to embrace contemporary technologies.
So what is a DBA to do in the new and foreboding modern world? How does one actually install Postgres into Kubernetes stack, and then what happens afterward? Well, there’s only one way to find out!
A Quick Introduction
In order to use Postgres effectively in Kubernetes, one needs an Operator to control all of the related resources, failover, connection pools, stored secrets, and a number of other components. Every major player in the Postgres industry has one, all with various strengths, and EDB is no different in that regard. The principal calling card of CloudNativePG from EDB is it is currently the only “native” Kubernetes operator, written entirely in Go and calling upon multiple native Kubernetes interfaces as a peer service.
EDB unleashed CloudNativePG on the world on April 22nd, 2022, but we’d been working on it for over a year before that. The first 1.0 release came on February 4th, 2021, and that doesn’t include prototypes and other internal or proprietary products before the current incarnation. We had a working BDR operator as early as January of 2020, in fact! Gabriele Bartolini wrote a blog post detailing the long and sordid history, and it’s definitely been an eventful few years.
With a development history like that, it should be pretty easy to use, right? Let’s see!
Kubernetes Crash Course
The best way to learn something is to use it. Due to its popularity, there are a myriad of Kubernetes analogs out there to choose from. The easiest is probably kind, which spins up an entire Kubernetes instance in a Docker container. After that comes minikube, which takes a similar approach but tends to prefer provisioned VMs. And then there’s K3s, essentially a trimmed down version of “real” Kubernetes k8s, but otherwise operates very similarly.
For pure experimentation purposes, any of those will suffice. For the brave and bold, K3s will provide a more “authentic” experience because it can easily operate as a fully operational cluster. And what does that experience entail?
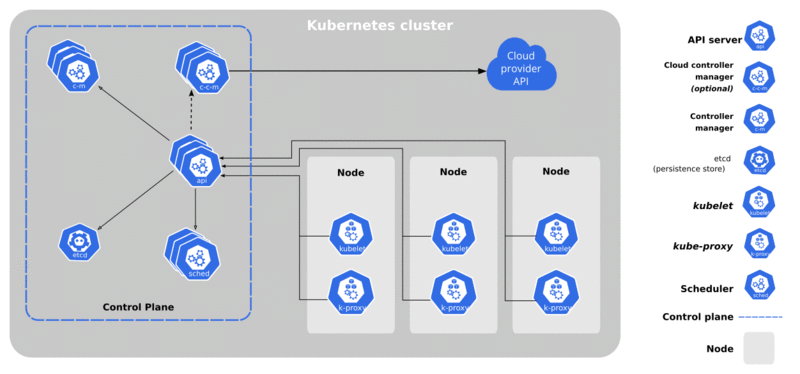
It looks complicated because it is. Yet we really only care about two things: the Control Plane, and Worker Nodes. The Control Plane usually consists of 3-5 nodes and basically tell all the Worker Nodes what to do, where services should deploy, how quorum is maintained, and so on. Losing the control plane means losing the entire cluster, so keep those systems healthy! Worker Nodes do everything else, usually related to hosting actual applications, compute, storage, and so on.
Getting one of these things up and running is beyond the scope of this article, but there are a plethora of blogs, tutorials, tools, YouTube videos, and other reference materials. For those comfortable with Ansible, Kubespray is a great tool to roll everything out in a standard and repeatable manner.
The last necessary tool is kubectl, which is essentially just a command-line utility for administering Kubernetes clusters. Finally, many administrators find Helm very handy as a kind of Kubernetes package manager.
Now that you’ve got a cluster up and running, what comes next?
Yet Another Markup Language
Better get comfortable with YAML, because that’s the lingua franca in the land of Kubernetes. As of this writing, the most recent version of CloudNativePG is 1.22. Installation instructions are tied directly to the version, but this is easily found in the documentation. And those instructions are no lie: installing CloudNativePG requires only one command.
Here’s how we installed and verified the operator:
$> kubectl apply -f https://raw.githubusercontent.com/cloudnative-pg/cloudnative-pg/release-1.22/releases/cnpg-1.22.1.yaml
$> kubectl get deployment -n cnpg-system
NAME READY UP-TO-DATE AVAILABLE AGE
cnpg-controller-manager 1/1 1 1 26hBelieve it or not, at this point, all we need to do is write the configuration for the cluster we want to deploy. That sounds like an oppressive task, but again the documentation comes to the rescue. It includes multiple functional examples with lots of variation for what kind of options we may want, what parameters and components are available, and so on.
This is also where we got a bit creative. Longhorn is one of the more popular storage classes in Kubernetes. It’s an object-store which supports incremental backup, snapshots, block replication, and most of the other storage-related buzzwords expected these days. However, as the CloudNativePG docs suggests, volume replication should be effectively disabled when using this kind of storage.
An easy way to do this is to actually create a second storage class with only that specific option changed. We used this definition, and then injected it with “kubectl apply -f.”
apiVersion: v1
kind: ConfigMap
metadata:
name: longhorn-storageclass-1r
namespace: longhorn-system
labels:
app.kubernetes.io/name: longhorn
app.kubernetes.io/instance: longhorn
app.kubernetes.io/version: v1.5.3
data:
storageclass.yaml: |
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-1r
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: driver.longhorn.io
allowVolumeExpansion: true
reclaimPolicy: "Delete"
volumeBindingMode: Immediate
parameters:
numberOfReplicas: "1"
staleReplicaTimeout: "30"
fromBackup: ""
fsType: "ext4"
dataLocality: "disabled"All we did was take the definition for the standard Longhorn storage class and changed the name so it would be created as a new entry, and then reduced the amount of replicas to 1. This means there will only ever be one copy of the data. This is fine and even desired for Postgres, since each Postgres replica has its own copy of the entire data folder. We used “1r” to signify the amount of replicas – very creative, we know.
Postgres Kubed
Now it’s time to add our Postgres cluster to Kubernetes. We came up with what we think is a balanced definition, so let’s walk through the various sections.
Let’s start with the preamble:
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: test-cnpg-cluster
namespace: cloudnative-pgWe plan to name this cluster “test-cnpg-cluster” appropriately enough. CloudNativePG will deploy the cluster into the “default” namespace, but we like to be good citizens, so we elect to use a different one instead. Everything after this will describe the actual cluster definition.
spec:
instances: 3
bootstrap:
initdb:
database: bones
owner: bonesWe should place all components of our cluster definition within the “spec” section of the file. In this case, we decided to create a cluster of three members. We also didn’t want the default “app” database, so chose one of our own, and changed the default database owner while we were at it. Next, we want to tweak some Postgres configuration parameters slightly:
postgresql:
parameters:
random_page_cost: "1.1"
log_statement: "ddl"
log_checkpoints: "on"Our Kubernetes cluster has access to nice and speedy SSD storage, so it makes sense to reduce the cost of retrieving random pages. We also like logging any statement that modifies the database, and any checkpoints for forensic purposes. We can add nearly any valid configuration parameter here, and it will be faithfully applied to the cluster. If we add further parameters in the future, the operator will apply either a reload or restart to each node, depending on what we changed.
affinity:
nodeSelector:
longhorn: "true"Setting node affinity is one of the esoteric arts of Kubernetes, telling applications and storage where they should reside. In this case we chose something simple rather than relying on distribution, balance score, or other advanced techniques. Kubernetes allows you to label nodes with various tags for management purposes, and we chose to mark all nodes with Longhorn storage enabled so we can take advantage of them specifically. In a more Production environment, perhaps we would target “database” instead, as such nodes would presumably be configured with necessary prerequisite services.
And speaking of Longhorn:
storage:
storageClass: longhorn-1r
size: 100Gi
walStorage:
storageClass: longhorn-1r
size: 20GiRather than the default storage, we specified that this cluster should reside in the special “longhorn-1r” storage class we created. We also split the data and WAL allocations, as all good Postgres DBAs should.
Now all we have to do is deploy the cluster:
kubectl create namespace cloudnative-pg
kubectl apply -f test-cnpg-cluster.yamlThe cluster should be up and running within a minute or two. Easy, right? All it took was about 30 lines of YAML and two commands to create an entire fault-tolerant, highly available cluster spread across three nodes. And in less than five minutes! Try that with anything else.
Getting Access
Deploying a cluster is one thing, actually accessing it is entirely another. CloudNativePG creates three services for every cluster, named after the cluster name. In our case, these are:
- test-cnpg-cluster-rw - Always points to the Primary node
- test-cnpg-cluster-ro - Points to only Replica nodes, chosen by round-robin
- test-cnpg-cluster-r - Points to any node in the cluster, chosen by round-robin
Kubernetes has its own DNS to route these aliases, so we just need to use these names to connect as desired. If the application isn’t in its own namespace, we just treat the namespace like a FQDN. So if we want to connect to the Primary from some other namespace, we would use: test-cnpg-cluster-rw.cloudnative-pg.
The documentation on Connecting from an application goes into more detail. But what if we have a legacy app that isn’t in Kubernetes, or Heaven forbid, we want to connect directly? As with most things in Kubernetes, there are several ways to address this. There is a section on Exposing Postgres Services in the manual, and the idea is to define an ingress method so Kubernetes knows how to route outside access to the correct service identifier.
This can be accomplished through ingress-nginx, Traefik, MetalLB, or any number of popular ingress layers. Chances are a home system has one or more of these installed. We decided to use MetalLB because it’s one of the easiest ways to get a static IP linked to our internal service. Creating the route is just one kubectl command away:
kubectl -n cloudnative-pg expose service test-cnpg-cluster-rw \
--name=test-cnpg-bones-lb --port=5432 --type=LoadBalancerThe benefit of using this command is that we don’t have to specify or care how Kubernetes fulfills the request. Just so long as there’s a compatible LoadBalancer type available, it’ll expose the Primary cluster service to the world and assign an IP. Now here’s what our list of services looks like:
NAME TYPE EXTERNAL-IP PORT(S)
test-cnpg-bones-lb LoadBalancer 10.0.5.101 5432:32631/TCP
Test-cnpg-cluster-r ClusterIP <none> 5432/TCP
test-cnpg-cluster-ro ClusterIP <none> 5432/TCP
test-cnpg-cluster-rw ClusterIP <none> 5432/TCPNote how there’s a new service named as we requested and tied to an IP address. We can connect to this, but now there’s a new problem: what’s the password? If we don’t specify one, CloudNativePG will generate a password and store it within a Kubernetes secret. These are locked down in various ways to ensure only the owner or should be able to access them, but that doesn’t quite help us. How do we get the information?
If our cluster has a front-end management suite like Rancher, we should be able to simply navigate through the interface and copy the secret into our clipboard. Barring this, kubectl comes to the rescue yet again. We can see the list of secrets created by CloudNativePG:
$> kubectl -n cloudnative-pg get secret
NAME TYPE DATA AGE
test-cnpg-cluster-app kubernetes.io/basic-auth 9 71m
test-cnpg-cluster-ca Opaque 2 71m
test-cnpg-cluster-replication kubernetes.io/tls 2 71m
test-cnpg-cluster-server kubernetes.io/tls 2 71mIf we ignore the certificate-related elements, we’ll see that the test-cnpg-cluster-app secret contains everything we need, including the username and password. We can use some JSON-parsing magic to get the password string we want:
kubectl get secret test-cnpg-cluster-app \
-o=jsonpath='{.data.password}' | base64 -dWe can export that as the PGPASSWORD environment variable or copy and paste it into a psql or pgAdmin password prompt. Either way, we should now be able to connect to our cluster as well.
$> export PGPASSWORD=<snip>
$> psql -h 10.0.5.101 -U bones -d bones
psql (16.2 (Ubuntu 16.2-1.pgdg22.04+1))
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off)
Type "help" for help.
bones=>Success!
Final Words
There’s obviously a lot more we could cover here. The last time we checked, CloudNativePG is the only Kubernetes operator that doesn’t rely on Patroni for managing cluster state. This gives it direct access to failover management, provisioning persistent volume claims, handling system snapshots, load balancing, and several other abilities that are only available at the operator level. Gabriele and his team have been pushing the bleeding edge for five years now, with no sign of stopping. You could say Gabriele is helping ensure EDB is dedicated to marrying Postgres to Kubernetes.
We leveraged that fanaticism in this article to evolve from knowing very little about Kubernetes or CloudNativePG to deploying a whole cluster and learning how to access it. The next thing we should probably do at this point is install the cnpg kubectl plugin, as that simplifies many Postgres cluster management operations.
Our work as DBAs is never done, and the ecosystems we must tame are always mutating over time. Despite its perceived complexity, Kubernetes significantly simplifies many tasks we’d normally perform. No more configuring complex HA stacks and hoping we got all of the quorum, fencing rules, helper scripts, routing, and everything else right on each node. No more fighting with individual nodes; we can address the cluster as a cluster, the way it was always meant to be.
We should still familiarize ourselves with the underlying infrastructure of how Kubernetes works, especially in relation to CloudNativePG. The documentation is a great help in this regard, and it’s impossible to browse the internet without tripping over dozens of Kubernetes blogs, tutorials, and YouTube videos. The information is there, should we pursue it.
For now at least, the future of Postgres is calling, and EDB is helping to make it happen. Read this insightful blog post on the journey of CloudNativePG, detailing its exciting development history. With such a rich background, using it should be straightforward—let's find out!
CloudNativePG FAQ
CloudNativePG is a Kubernetes operator specifically designed for managing PostgreSQL databases in cloud-native environments. It is developed by EDB and offers tools to handle failover mechanisms, connection pools, and more.
CloudNativePG is unique because it is the only native Kubernetes operator written entirely in Go and doesn't rely on Patroni for managing cluster states, making it robust and efficient.
Key features include automatic failover management, persistent volume claims, system snapshots, and load balancing. It's designed to simplify database management in Kubernetes environments.
Installing CloudNativePG is straightforward. It involves a single command, and detailed instructions can be found in the official documentation.
Yes, CloudNativePG is adept at managing multiple cloud-native PostgreSQL databases, making it ideal for complex applications requiring multiple database instances.
Tools like kind, minikube, and K3s are recommended for experimentation. These tools simulate a Kubernetes environment, making them excellent for learning and testing.
CloudNativePG allows you to define and deploy PostgreSQL clusters within Kubernetes. It supports custom configurations and node affinity settings to optimize performance.
YAML is used extensively for configuring Kubernetes resources and deploying CloudNativePG. It's crucial for defining cluster components and settings.
CloudNativePG creates several services for cluster access, using Kubernetes DNS to provide aliases for connecting. It supports connections from different namespaces and even external applications through ingress methods.
Popular ingress solutions include ingress-nginx, Traefik, and MetalLB. These help in routing external access to the appropriate PostgreSQL services.
CloudNativePG deploys fault-tolerant clusters across multiple nodes, ensuring high availability and resilience against failures.
Yes, CloudNativePG is designed for production use, offering features that ensure reliability and performance in demanding environments.
Its native integration with Kubernetes, ease of use, and comprehensive feature set have made CloudNativePG a favored choice for managing PostgreSQL databases in cloud-native environments.