Postgres in the time of monster hardware

I don't know if you followed the release of the last generation of CPUs. AMD's latest Genoa CPU (AMD EPYC™ 9965) can run 768 threads. It has 192 cores per socket and 2 threads per core, with 2 sockets. Imagine adding 10 TB of RAM to such a beast! Of course, everyone will think of how useful it will be for virtualization. As a database person, I'd rather ask myself what Postgres could do with so many resources. I love simplicity in architecture. But I often meet customers with huge resource needs. With average hosts nowadays, the best answer for them is sometimes multi-parallel processing (MPP).
So, with this new hardware, can we stop using horizontal scalability? To understand the impact of running PostgreSQL on it, we must examine a few technical limits. The analysis will begin with NUMA (Non-Uniform Memory Access) architecture. Next, we will address I/O bandwidth limits. They are a big factor, no matter the CPU or memory. Next, we will look at how PostgreSQL behaves with many connections. This topic has historical limits that bring up key questions. Finally, we will test parallel queries. We will examine their scalability and effectiveness on systems with many CPU threads.
The known painful point: Non-uniform memory access (NUMA)
What is NUMA?
In the prehistoric days of computing, there was only one CPU per socket. Most systems had only one socket. So, there was no conflict to access the memory. Then, someone had the idea to have 2 sockets. This would let the same hosts use 2 CPUs, thus doubling a computer's processing power! Every processor needs memory to work. Each computer had one memory pool, so designers decided that each core, which was monocore CPUs at the time, would access memory one at a time. They could access any part of the memory, though. This was called UMA for Uniform Memory Access.
Then we created more and more cores per CPU, and we added more and more sockets. The problem that occurred was that to access the memory, each core had to go through a kind of road called a "bus." And, as CPUs improved and multiplied, this bus became a bottleneck for performance.
That's where we invented NUMA for non-uniform memory access. The idea is that we partition the memory into zones called NUMA nodes. Each core has access to one NUMA node that is physically closer to it, referred to as the local NUMA node. But should a core need more memory, it can still access other NUMA nodes, called remote NUMA nodes. Accessing a local NUMA node is simple and fast. But, accessing a remote NUMA node is harder and slower.
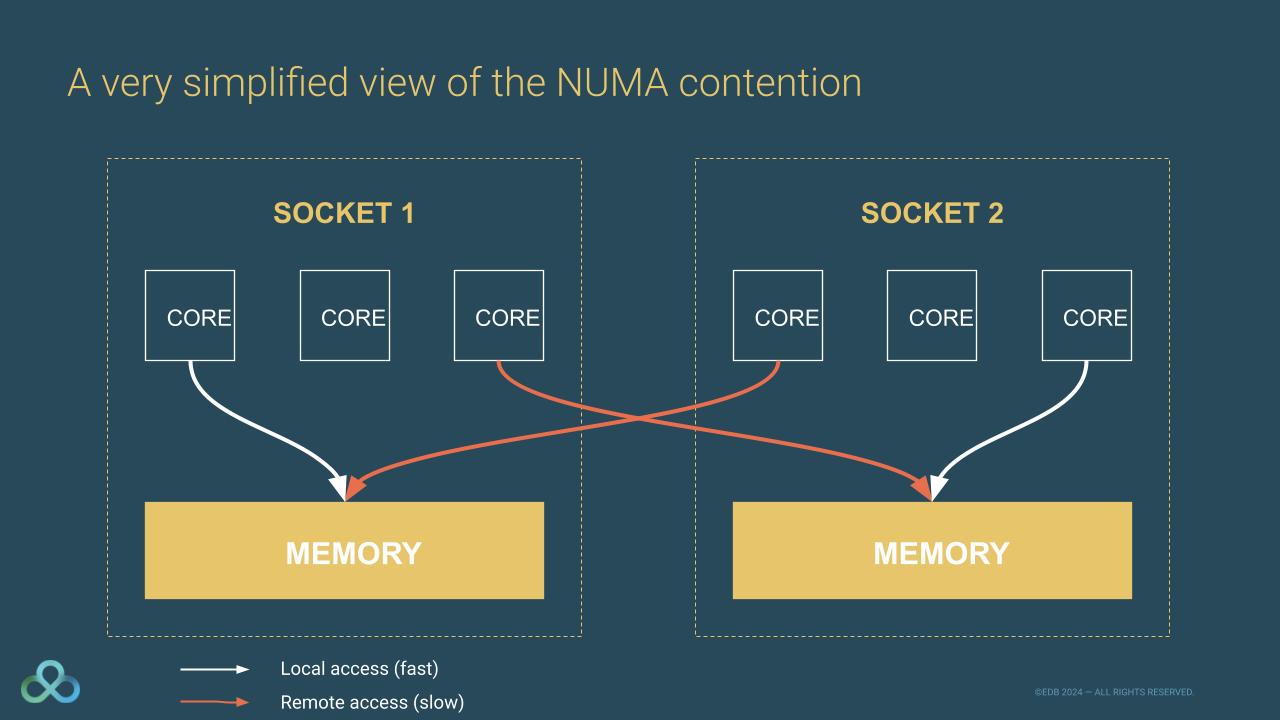
Let me use an analogy with 4-year-old children to explain NUMA better. Let's say for the sake of the argument that you have to take care of 4-year-old toddlers who need to access toys. To ensure a great playing experience, you will make a turn to who will have access to the toybox and when. This system works fine with 2 toddlers. Now let's assume you have 20 toddlers. This system won't work. It will make them wait too long. Anyone who's seen a 4-year-old knows how quickly they can grow impatient! Every preschool teacher will say the solution is simple: give each child their own toybox. They can still access the others, if needed and allowed. This is how NUMA works.
What about PostgreSQL?
When developers created PostgreSQL, NUMA didn't exist. PostgreSQL often uses a lot of memory, especially in shared buffers. Those shared buffers are very important. They are shared between all PostgreSQL processes. But as shared buffers are allocated at the start of PostgreSQL, the shared buffers will be allocated in the NUMA node of the postmaster process. This is particularly true if you use the extension pg_prewarm. This extension preloads tables or indexes into PostgreSQL's shared buffer cache to improve performance. When you fork the postmaster to create new connections, they will have access to shared_buffers. But, it might not be "near" them, so it might be slower.
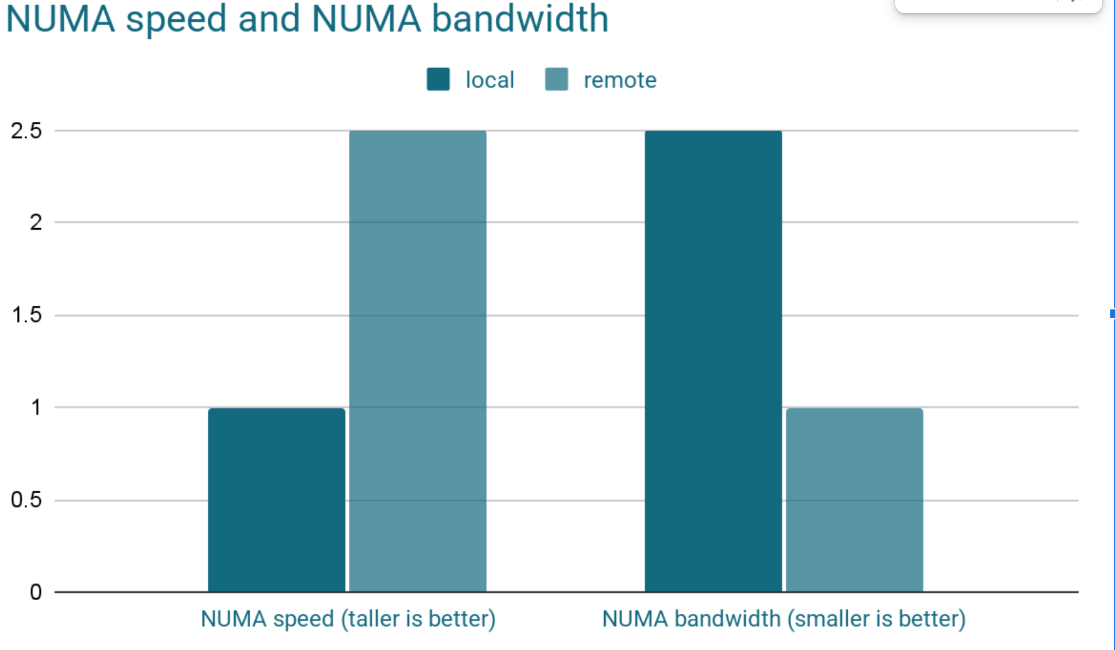
How much slower is it? There are 2 aspects to that question. The first one is simple: accessing the local NUMA node is faster than accessing another NUMA node. Manufacturers' spec sheets say it takes 50-100 ns to access its own NUMA node. Accessing a remote NUMA node is 2 to 3 times slower. Also, memory bandwidth is slower when accessing a remote NUMA node than a local one. Let's say for the sake of demonstration that each remote NUMA access takes 200 ns in latency. It doesn't feel like much. But Postgres will likely do that millions of times per query. Should you multiply those 200 ns by 1 million times, you will already get a 200 ms latency. The second aspect is memory bandwidth. Manufacturer specs show 50 GB/s bandwidth to the local NUMA. It drops to 20 GB/s for a remote NUMA node.
Then we have locks. To prevent some memory corruption, memory allocation requires some locks. It is not a problem if the CPU can process other orders while waiting for the lock, but it is not always the case. Processing a hash table needs a lot of memory. It can’t continue without acquiring that lock. As hash tables need to change a lot of data in memory, it will require a lock each time.
The existing hardware limitation: I/O bandwidth
In my experience as a DBA, a database consultant, and a Postgres firefighter, most bottlenecks come from I/O. Even super-fast SSDs are slower than RAM. This creates I/O contention.
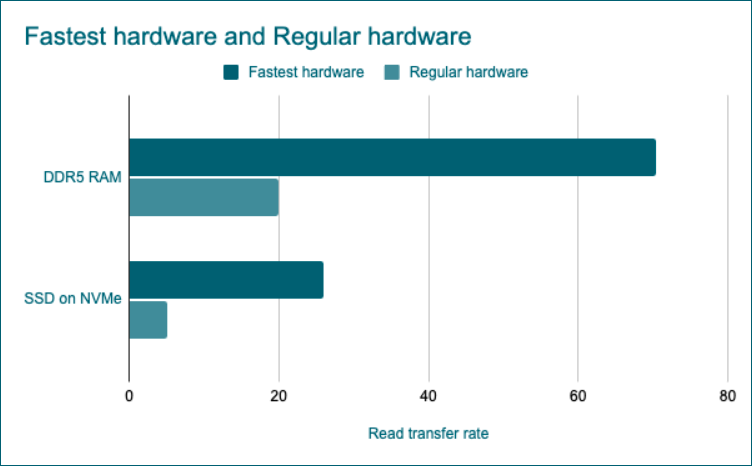
The latest DDR5 RAM generation (manufacturer numbers) has a transfer rate of 70.4 GB/s for sequential reads. While the fastest SSD (PCIe gen 6) over NVMe will only read at 26 GB/s (for sequential reads too). That's almost three times slower! But that's only for the fastest hardware you can find! Most of the time, your RAM will have a transfer rate of 10 to 30 GB/s, while your SSD on NVMe will be between 2 to 5 GB/s.
Then there is the problem of disk reliability. An SSD is meant to be used for a certain number of writes, after which it will fail. You don't want to lose your data should your disk horribly die! So we created RAID (redundant array of independent disks).
RAID has several levels. For databases, RAID10 is best. It balances speed and reliability by combining striping and mirroring. It means that each block is written twice (each time on a different disk). Of course, it takes a little more time to write a block twice than to write it once. This means that writes are even slower on disk than in memory.
So, we clearly have a problem here. I don't recommend not using RAID10 and/or disabling fsync for speed. If your server crashes or you lose a disk, you would lose data. Typically, that's not what most PostgreSQL users want. So, unless the storage industry progresses, this limit will apply. And it will likely prevent PostgreSQL from using the great resources you can provide.
The huge unknown: connections count
PostgreSQL is well-known for not being very good with many connections. It does not mean you can't do great things with PostgreSQL. But, for a transactional workload, we always tell customers to use a connection pooler. If you need to pick one, pgBouncer is a great choice. If you are developing in Java, try the pooler integrated into your JDBC driver.
I got a call for an emergency meeting from a customer. Their PostgreSQL Linux resources were maxed out, and everything was slow. The host was quite limited in resources regarding the performance they were expecting. We found a misconfiguration in the connection pooler. It was creating and deleting tens of thousands of connections per second. At least it was trying to. I had to explain that the limit came from Linux. It couldn't fork so many processes in such a short time. The solution was simply to configure the JDBC connection pooler the right way.
But, what if we could have scaled vertically to 768 threads and used 10 TB of RAM? Would Linux and Postgres have been able to leverage all those resources? I can't tell. In theory, being able to add more autovacuum workers will help databases with more tables. In theory, each new connection creates a new process. This adds more CPU threads, so you can run more processes. But when you enter unknown territories like this, the probability of an unknown bug/inefficiency is higher. That's valid for Postgres but also for Linux, which Postgres relies heavily on. If you want to explore low-level performance investigations, check out this academic paper and the slides from the conference talk titled "An analysis of Linux scalability to many cores." Of course, EDB is there to work with you to fix such issues, and this will help the community too! You can read the story of the fixing of such a performance bug here.
The 'it depends' factor: parallelizing queries
Parallelizing a query needs some extra resources and time. It is to gather the results and synchronize the workers. For example, you wouldn't want a simple select count(*) from tableA query to count twice the items from one page! This adds a small overhead to all parallelized queries. This overhead, though small, can be significant for some queries but negligible for others.
From my and my colleagues' experience, the Postgres optimizer still has some issues with finding out which query will benefit from parallelizing and which query will be slower. You can try to tune the optimizer to make it learn how to behave for your specific workload, but this is not trivial (sadly).
So, what kind of queries will benefit from parallelizing? Queries on large (or partitioned) tables will likely enjoy parallelization. Queries on small tables likely won't. Analytics workloads that process large data with aggregates might benefit from parallelizing or not. It depends on your data. Transactional workloads usually process small queries that are unlikely to benefit from parallelization. But there are exceptions!
PostgreSQL documentation advises not to use more than a few thousand partitions. For native partitioning, there is an undocumented limit of 64k per partition for one table in the same query. You can check the bug report here.
So, my only advice here will be to benchmark your application with your real workload. Also, keep in mind that you can't be faster than your slowest hardware. It is likely that many CPUs won't help should your bottleneck be I/O.
To conclude
Today, the database world relies heavily on massively parallel processing (MPP) solutions. They are essential for managing large workloads. With powerful hardware like AMD's new Genoa CPU, offering 768 threads and the chance for terabytes of RAM, we could be on the brink of a big change. It's tough to picture a world without MPP today. But in the next 1-3 years, we might see big changes in how we view database architecture.
These incredible hardware capabilities might allow us to simplify our architectures significantly. Instead of managing complex distributed systems, we could potentially handle massive workloads on a single, well-tuned PostgreSQL instance. The prospect is exciting. It means fewer moving parts, simpler maintenance, and possibly more predictable performance.
However, as with any technological evolution, the key to success lies in thorough testing and validation. Every workload is unique, and what works brilliantly for one application might not be optimal for another. That's why benchmarking remains absolutely crucial. You need to understand not just how your application performs today, but how it might scale with these new resources.
The good news is you don't have to figure this out alone. The EDB team is here to help you navigate these waters. Whether you're encountering performance issues, need help with benchmarking, or want to explore the possibilities of these new hardware configurations, our experts can work with you to find the optimal solution for your specific needs. After all, we've been helping customers push PostgreSQL's boundaries for years, and we're excited to see what these new hardware capabilities might unlock.
Remember, there's no one-size-fits-all solution. But with proper testing, expert guidance, and the right hardware-software combination, you might find that the future of your database architecture is simpler and more powerful than you imagined. The key is to benchmark, test, and validate - and we're here to help you every step of the way.